I implemented a Vulkan multi-threaded rendering, which was basically based on the multi-threaded rendering of the Sascha Willems demo(Vulkan/examples/multithreading at master · SaschaWillems/Vulkan · GitHub)
The method I implemented is to allocate a PrimaryCommandBuffer, and then each rendering thread has its own CommandPool and SecondaryCommandbuffers for submit rendering.
I posted some code here if anyone want to see the details of my implementation.
【PrimaryCommandBuffer dispatch code】
bool KVulkanRenderDevice::SubmitCommandBufferMuitiThread(unsigned int imageIndex)
{
assert(imageIndex < m_CommandBuffers.size());
KVulkanRenderTarget* target = (KVulkanRenderTarget*)m_SwapChainRenderTargets[imageIndex].get();
VkRenderPassBeginInfo renderPassInfo = {};
renderPassInfo.sType = VK_STRUCTURE_TYPE_RENDER_PASS_BEGIN_INFO;
renderPassInfo.renderPass = ((KVulkanRenderTarget*)m_SwapChainRenderTargets[imageIndex].get())->GetRenderPass();
renderPassInfo.framebuffer = target->GetFrameBuffer();
renderPassInfo.renderArea.offset.x = 0;
renderPassInfo.renderArea.offset.y = 0;
renderPassInfo.renderArea.extent = target->GetExtend();
auto clearValuesPair = target->GetVkClearValues();
renderPassInfo.pClearValues = clearValuesPair.first;
renderPassInfo.clearValueCount = clearValuesPair.second;
VkCommandBuffer primaryCommandBuffer = m_CommandBuffers[imageIndex].primaryCommandBuffer;
VkCommandBufferBeginInfo cmdBufferBeginInfo = {};
cmdBufferBeginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
VK_ASSERT_RESULT(vkBeginCommandBuffer(primaryCommandBuffer, &cmdBufferBeginInfo));
{
vkCmdBeginRenderPass(primaryCommandBuffer, &renderPassInfo, VK_SUBPASS_CONTENTS_SECONDARY_COMMAND_BUFFERS);
{
VkCommandBufferInheritanceInfo inheritanceInfo = {};
inheritanceInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_INHERITANCE_INFO;
inheritanceInfo.renderPass = ((KVulkanRenderTarget*)m_SwapChainRenderTargets[imageIndex].get())->GetRenderPass();
inheritanceInfo.framebuffer = ((KVulkanRenderTarget*)m_SwapChainRenderTargets[imageIndex].get())->GetFrameBuffer();
for(size_t i = 0; i < m_ThreadPool.GetWorkerThreadNum(); ++i)
{
m_ThreadPool.SubmitTask([=]()
{
ThreadRenderObject((uint32_t)i, imageIndex, inheritanceInfo);
});
}
m_ThreadPool.WaitAllAsyncTaskDone();
std::vector<VkCommandBuffer> commandBuffers;
size_t numThread = m_ThreadPool.GetWorkerThreadNum();
for(size_t threadIndex = 0; threadIndex < numThread; ++threadIndex)
{
ThreadData& threadData = m_CommandBuffers[imageIndex].threadDatas[threadIndex];
commandBuffers.insert(commandBuffers.begin(),
threadData.commandBuffers.begin(),
threadData.commandBuffers.end());
}
vkCmdExecuteCommands(primaryCommandBuffer, (uint32_t)commandBuffers.size(), commandBuffers.data());
}
vkCmdEndRenderPass(primaryCommandBuffer);
}
VK_ASSERT_RESULT(vkEndCommandBuffer(primaryCommandBuffer));
return true;
}
【SecondaryCommandbuffer submit code】
void KVulkanRenderDevice::ThreadRenderObject(uint32_t threadIndex, uint32_t imageIndex, VkCommandBufferInheritanceInfo inheritanceInfo)
{
ThreadData& threadData = m_CommandBuffers[imageIndex].threadDatas[threadIndex];
VkCommandBufferBeginInfo beginInfo = {};
beginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
beginInfo.flags = VK_COMMAND_BUFFER_USAGE_RENDER_PASS_CONTINUE_BIT | VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT;
beginInfo.pInheritanceInfo = &inheritanceInfo;
for(size_t i = 0; i < threadData.num; ++i)
{
VkCommandBuffer commandBuffer = threadData.commandBuffers[i];
VK_ASSERT_RESULT(vkBeginCommandBuffer(commandBuffer, &beginInfo));
KVulkanRenderTarget* target = (KVulkanRenderTarget*)m_SwapChainRenderTargets[imageIndex].get();
{
KVulkanPipeline* swapchainPipeline = (KVulkanPipeline*)m_SwapChainPipelines[imageIndex].get();
VkPipeline pipeline = swapchainPipeline->GetVkPipeline();
VkPipelineLayout pipelineLayout = swapchainPipeline->GetVkPipelineLayout();
VkDescriptorSet descriptorSet = swapchainPipeline->GetVkDescriptorSet();
vkCmdBindPipeline(commandBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, pipeline);
vkCmdBindDescriptorSets(commandBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, pipelineLayout, 0, 1, &descriptorSet, 0, nullptr);
KVulkanVertexBuffer* vulkanVertexBuffer = (KVulkanVertexBuffer*)m_VertexBuffer.get();
VkBuffer vertexBuffers[] = {vulkanVertexBuffer->GetVulkanHandle()};
VkDeviceSize offsets[] = {0};
vkCmdBindVertexBuffers(commandBuffer, 0, 1, vertexBuffers, offsets);
KVulkanIndexBuffer* vulkanIndexBuffer = (KVulkanIndexBuffer*)m_IndexBuffer.get();
vkCmdBindIndexBuffer(commandBuffer, vulkanIndexBuffer->GetVulkanHandle(), 0, vulkanIndexBuffer->GetVulkanIndexType());
glm::mat4& model = m_ObjectFinalTransforms[i +threadData.offset];
vkCmdPushConstants(commandBuffer, pipelineLayout, VK_SHADER_STAGE_VERTEX_BIT, 0, (uint32_t)m_ObjectBuffer->GetBufferSize(), &model);
vkCmdDrawIndexed(commandBuffer, static_cast<uint32_t>(vulkanIndexBuffer->GetIndexCount()), 1, 0, 0, 0);
}
VK_ASSERT_RESULT(vkEndCommandBuffer(commandBuffer));
}
}
The same is to render 6400 small squares, multi-threaded rendering is significantly slower than single-threaded
Multi-threaded rendering results:
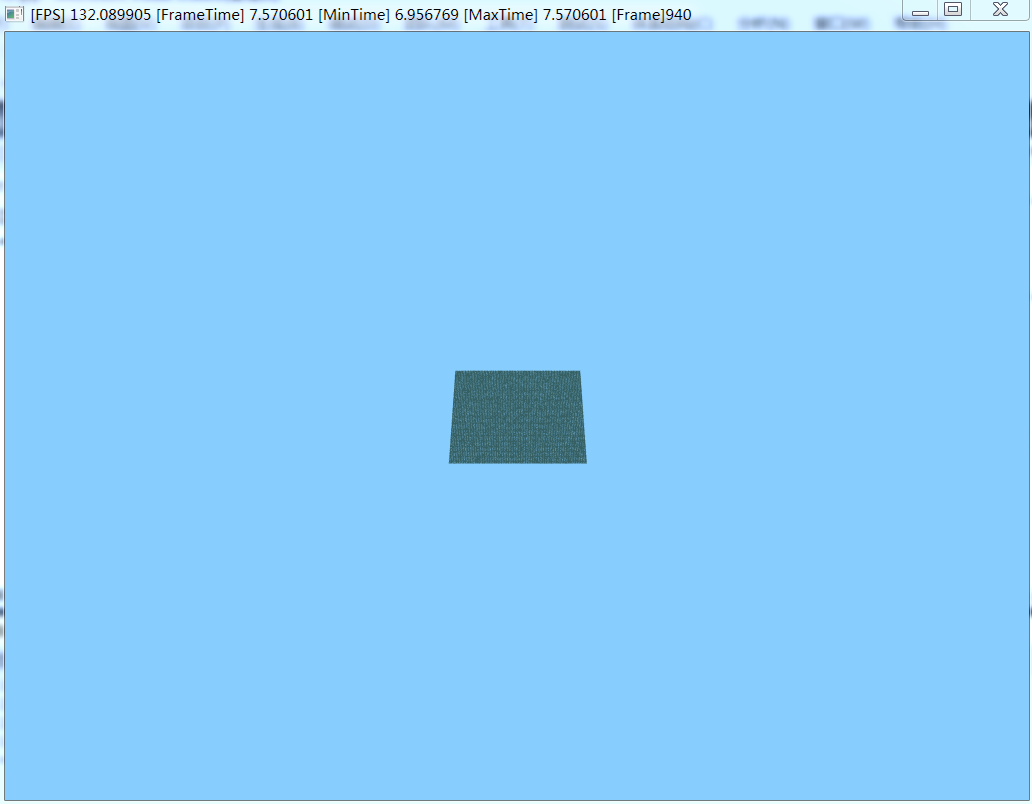
Single-threaded rendering results:
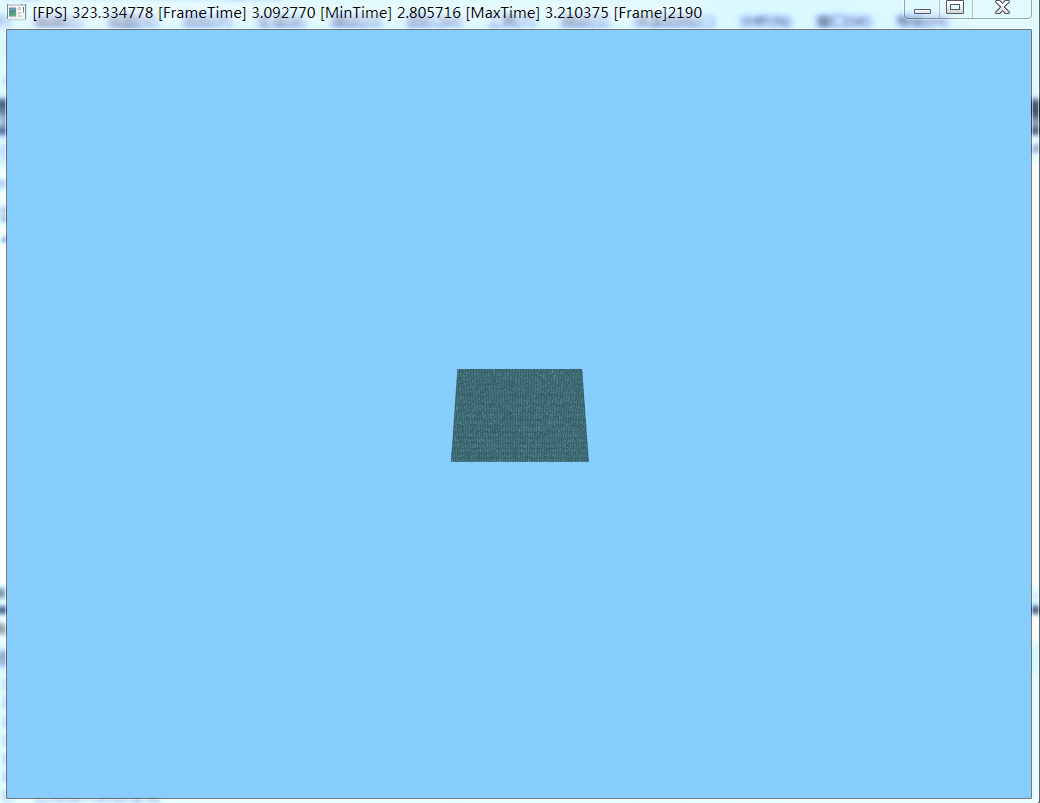
In order to profile this problem, I use vtune to see where the bottleneck is.
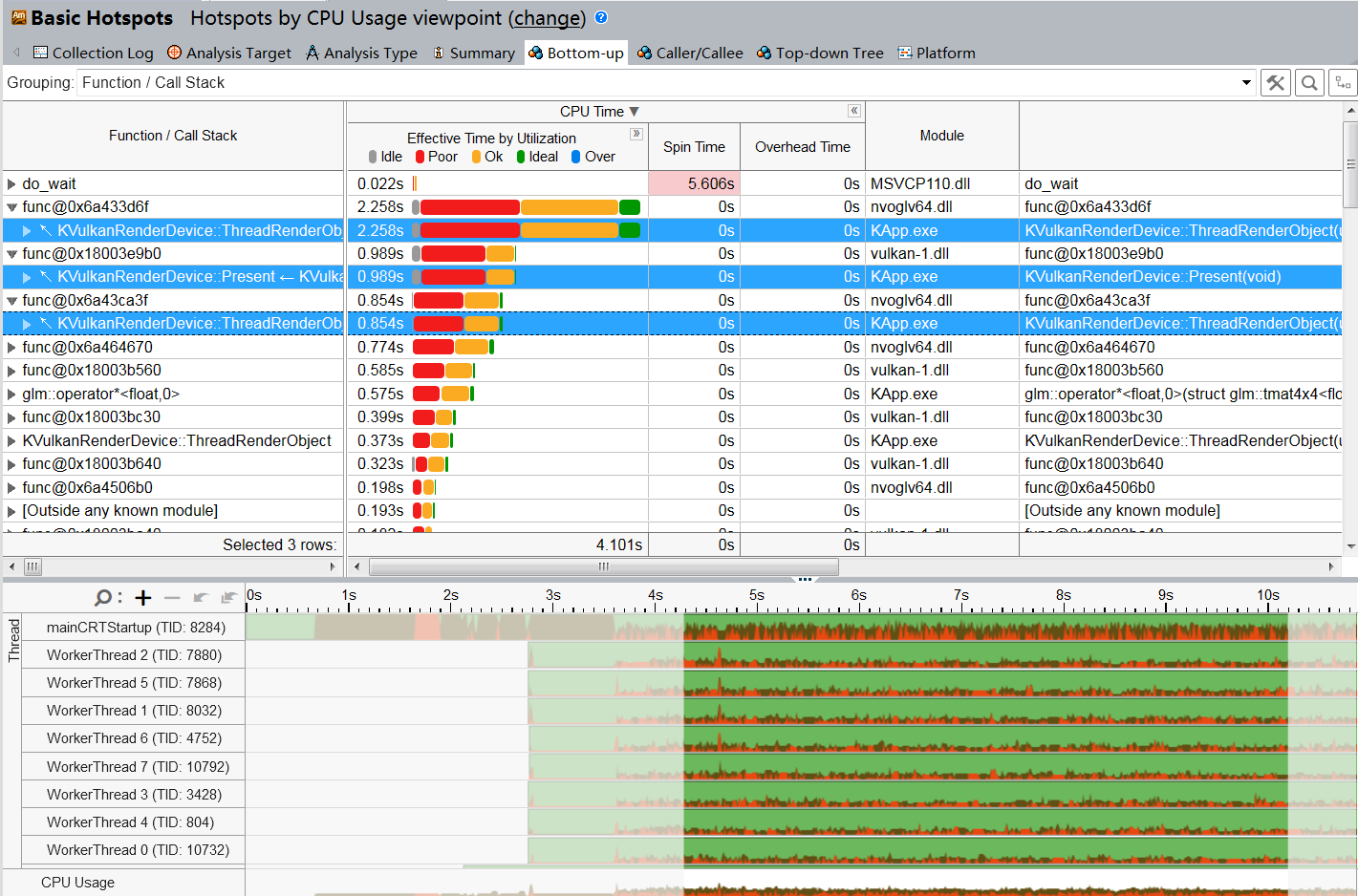
I found that the basic cause of performance bottlenecks is vkBeginCommandBuffer and
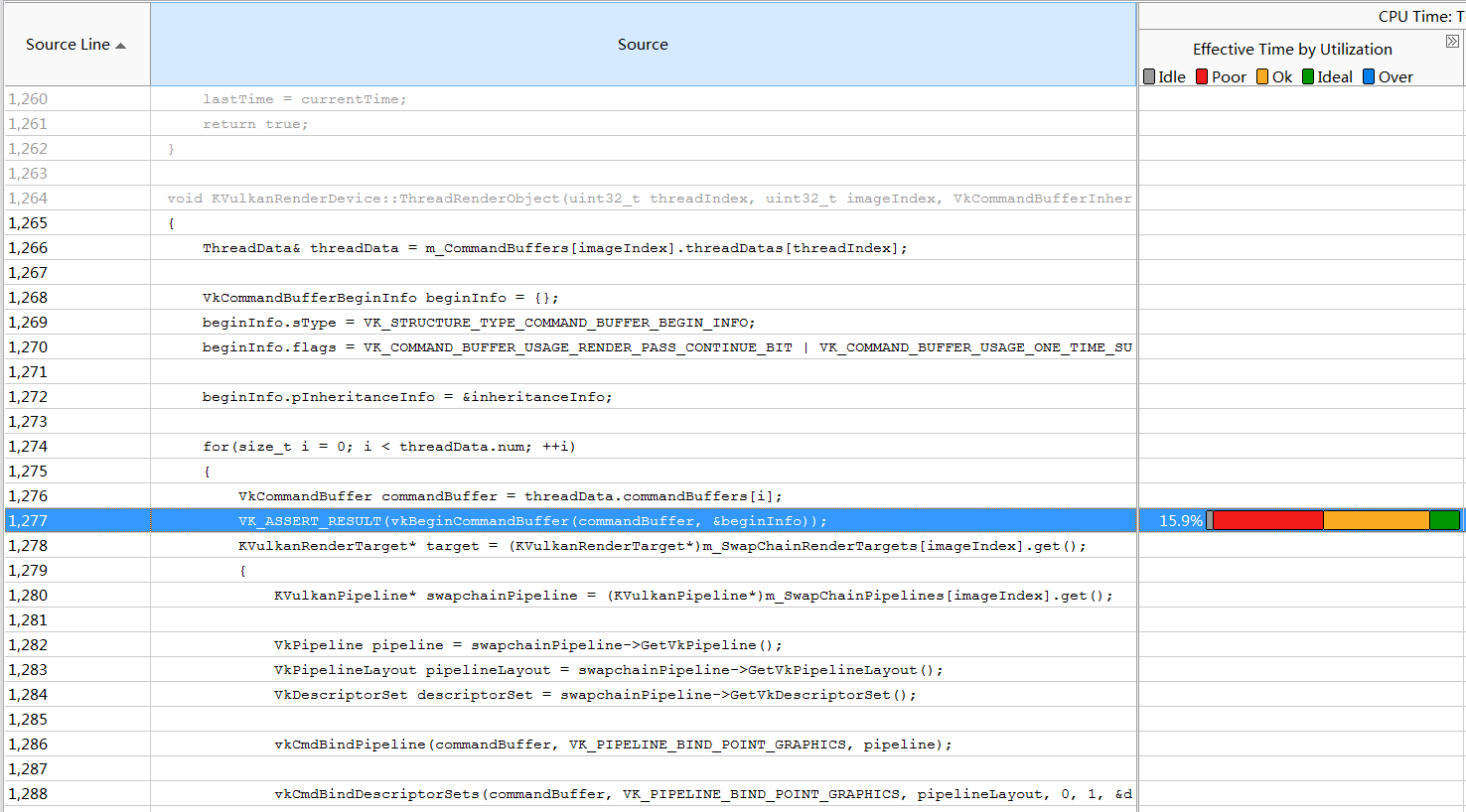
vkEndCommandBuffer in multithreaded rendering function

The rest is basically vkQueueSubmit.

For comparison, I went to profile the example of Sascha Willems.
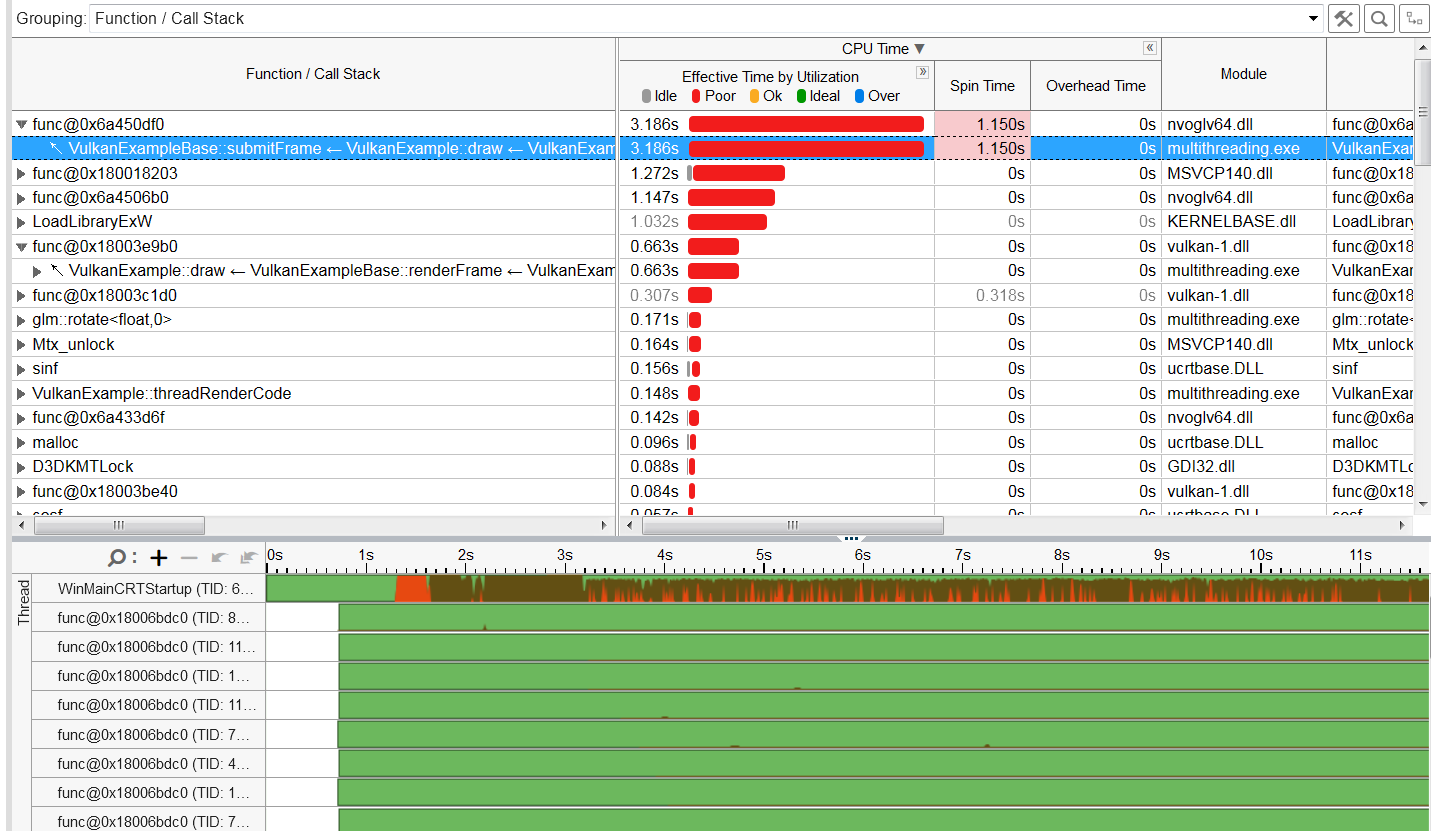
As you can see, vkBeginCommandBuffer and vkEndCommandBuffer are not a performance bottleneck, so you can see that his rendering thread does not have so much CPU time, which is very different from me.
Note that I have turned off the ValidationLayer for both and executed them all in the Release mode.
So I carefully compared my code with his code, there is basically no difference in the process, the parameters for creating CommandPool and Commandbuffer for rendering thread is also the same, how can there be such a completely different result. I have checked this issue for two days. Does anyone know exactly what may causes this result?