I am at the moment scratching my head why my multi-threaded command building doesn’t really translate in a performance win.
I have checked validation and my draw loop is in essence the very common
“acquire image → submit → present”
work division strategies are not really doing anything because according to my timing nearly all of the time of the draw loop is spent in vkQueuePresentKHR. How can this be with the lengthier command buffer building now done outside the loop in a threaded fashion. I know that I have a bunch of pre-built command buffers in wait as I fetch one in my loop, yet all time is in vkQueuePresentKHR.
it seems implausible to me that I hit already the ceiling of what the GPU can do with the model numbers as are in the single threaded scenario, even less plausible that there is not some gain from building across multiple threads.
does anybody with experience know what could cause a slowdown with all the expensive loops done outside the draw loop. as I said I ran memory checks and validation layer - I did turn off the validation afterwards, still I must have made some silly mistake, otherwise things should scale nicely. I refuse to think I have hit the ceiling already in a single threaded fashion.
I should also add that I have tried with and without fences, and rendering into 3 framebuffers. As is I just have the minimal semaphores for signalling.
Perhaps start by describing what exactly you have done, and how much performance you expected to gain by it in theory and why did you expected it. Then we can perhaps correct your preassumptions.
E.g. was the single core fully utilized by the singlethreaded code that you assumed multiple threads would help?
I am going to try to give more detail - unfortunately I upgraded Nvidia Nsight Systems on my linux yesterday and profiling doesn’t start any more (with the old version and same binary target it did) so I have to fix that first to get nice diagrams.
I can say one thing in regards to single threaded behavior however, here’s a few lines I logged showing that the burden is on the buffer creation (numbers are millis):
so I thought,well, it’s time to move the next best thing and below is the output from my first version of threading, which is just one dedicated thread pre-recording into a queue and the draw call fetching periodically to then submit and present with the burden now shifted (and numbers fluctuating a bit per loop execution) …
I will throw in a few other details until I get my profiling back, unaware of whether that info is useful for assessment or not. To be honest I have also no clue whether the overall number of triangles is considered large or not, all I know is that for 0-100 instances of the model I get ~140 frames/s, for 1000 about half that, and for 10K only 7 frames, so it seems like quite a degradation when going in up by a factor of 10.
I keep the vertex and index buffers device local
I tried out versions with model matrices as push constants vs SSBO offset - performance difference +/- 1 frame at most (at times)
For those measurements up there I drew 10,000 identical copies of a model (rotating) - I issue a draw call individually but then tried out the instance count with the SSBO version and got no performance difference there either (which was a bit of a surprise)
the model has around 19K triangles, and 7 textures
from what I could gather in various places I agree that this is not what is projected to happen, hence my surprise - I must have committed some blunder somewhere.
vkQueueSubmit duration is part of the overall “Frame” time in my example but not the buffer creation routine. it didn’t really stand out in a bad way in any of my measurements so far.
Thanks for your reply, I’m happy about any hints I can get.
For what it’s worth here is the draw routine loop - all that’s different compared to the single threaded execution is that instead of this->workerQueue.getNextCommandBuffer the buffer creation routine is called directly.
void Renderer::drawFrame() {
std::chrono::high_resolution_clock::time_point frameStart = std::chrono::high_resolution_clock::now();
uint32_t imageIndex;
VkResult ret = vkAcquireNextImageKHR(
this->logicalDevice, this->swapChain, IMAGE_ACQUIRE_TIMEOUT, this->imageAvailableSemaphores[this->currentFrame], VK_NULL_HANDLE, &imageIndex);
if (ret != VK_SUCCESS) {
if (ret != VK_ERROR_OUT_OF_DATE_KHR) {
logError("Failed to Acquire Next Image");
}
this->requiresRenderUpdate = true;
return;
}
ret = vkWaitForFences(this->logicalDevice, 1, &this->inFlightFences[this->currentFrame], VK_TRUE, UINT64_MAX);
if (ret != VK_SUCCESS) {
this->requiresRenderUpdate = true;
return;
}
ret = vkResetFences(this->logicalDevice, 1, &this->inFlightFences[this->currentFrame]);
if (ret != VK_SUCCESS) {
logError("Failed to Reset Fence!");
}
if (this->commandBuffers[imageIndex] != nullptr) {
this->workerQueue.queueCommandBufferForDeletion(this->commandBuffers[imageIndex]);
}
VkCommandBuffer latestCommandBuffer = this->workerQueue.getNextCommandBuffer(imageIndex);
std::chrono::high_resolution_clock::time_point nextBufferFetchStart = std::chrono::high_resolution_clock::now();
while (latestCommandBuffer == nullptr) {
std::chrono::duration<double, std::milli> fetchPeriod = std::chrono::high_resolution_clock::now() - nextBufferFetchStart;
if (fetchPeriod.count() > 500) {
logInfo("Could not get new buffer for quite a while!");
break;
}
latestCommandBuffer = this->workerQueue.getNextCommandBuffer(imageIndex);
}
if (latestCommandBuffer == nullptr) return;
this->commandBuffers[imageIndex] = latestCommandBuffer;
this->updateUniformBuffer(imageIndex);
VkSubmitInfo submitInfo{};
submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
VkSemaphore waitSemaphores[] = {this->imageAvailableSemaphores[this->currentFrame]};
VkPipelineStageFlags waitStages[] = {VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT};
submitInfo.waitSemaphoreCount = 1;
submitInfo.pWaitSemaphores = waitSemaphores;
submitInfo.pWaitDstStageMask = waitStages;
submitInfo.commandBufferCount = this->commandBuffers.empty() ? 0 : 1;
submitInfo.pCommandBuffers = &this->commandBuffers[imageIndex];
VkSemaphore signalSemaphores[] = {this->renderFinishedSemaphores[this->currentFrame]};
submitInfo.signalSemaphoreCount = 1;
submitInfo.pSignalSemaphores = signalSemaphores;
ret = vkQueueSubmit(this->graphicsQueue, 1, &submitInfo, this->inFlightFences[this->currentFrame]);
if (ret != VK_SUCCESS) {
logError("Failed to Submit Draw Command Buffer!");
this->requiresRenderUpdate = true;
return;
}
VkPresentInfoKHR presentInfo{};
presentInfo.sType = VK_STRUCTURE_TYPE_PRESENT_INFO_KHR;
presentInfo.waitSemaphoreCount = 1;
presentInfo.pWaitSemaphores = signalSemaphores;
VkSwapchainKHR swapChains[] = {this->swapChain};
presentInfo.swapchainCount = 1;
presentInfo.pSwapchains = swapChains;
presentInfo.pImageIndices = &imageIndex;
ret = vkQueuePresentKHR(presentQueue, &presentInfo);
if (ret != VK_SUCCESS) {
if (ret != VK_ERROR_OUT_OF_DATE_KHR) {
logError("Failed to Present Swap Chain Image!");
}
this->requiresRenderUpdate = true;
return;
}
this->currentFrame = (this->currentFrame + 1) % this->imageCount;
std::chrono::high_resolution_clock::time_point now = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> time_span = now -frameStart;
this->deltaTime = time_span.count();
int frameRate = static_cast<int>(1000 / this->deltaTime);
logInfo(std::to_string(frameRate));
}
ok, I was timing again, just to check vkQueueSubmit, and one thing that is worth noting is that when I took my previous timing it was based on the version with just semaphores.
Measuring again with the use of a fence on vkQueueSubmit changes nothing about the overall frame duration but shifts the time cost to vkWaitForFences instead of vkQueuePresentKHR.
How do you protect your semaphores against double use?
I see you index them by frame nr. modulo, but imageAvailableSemaphores[N] is used in acquire before vkWaitForFences, therefore it could be used twice for the same N. renderFinishedSemaphores[N] is kept by present until the same image shows up again, so it could also be used twice for the same N.
Thank you for pointing that out @krOoze, that order swap of vkWaitForFences with
vkAcquireNextImageKHR should have not happened, in fact I didn’t have that in my previous version.
Aside from that mistake, however, I believe the synchronization is correct, or did you mean to say you spotted more mistakes? The reason I ask is that this topic (despite reading up on it) is still one that I struggle with the most, and had on my list for potential issues, even more so when working with threads. Yet, I kept my code close to what seemed to be the general consensus out there in other code bases and tutorials. I shouldn’t need more than the semaphore wait and signalling for GPU and the fence for CPU-GPU to ensure that the queue execution after submit is finished, right?
Once again, thank you, I appreciate the time you are taking.
so most of the CPU time is spent in waiting for the fence but, well, I don’t see a way around that (seems dangerous), and, regardless, without it the wait would then shifts to vkPresentKHR (see second image below)…
Putting vkWaitForFences before vkAcquireNextImageKHR should protect imageAvailableSemaphores[]. The fence says the vkQueueSubmit that consumes the semaphore has finished.
renderFinishedSemaphores[] is consumed by vkPresent, so you have to make sure that finished (which happens after the fence, and cannot be caught by a fence anyway). There’s two ways to do it. You can have a semaphore per swapchain image, and if the same image returns from vkAcquire (and its semaphore has signaled), you can be reasonably sure the present has finished (though it is not explicitly spelled out in the Vulkan specification). Second way is to use the new presentID extension which tells you when it finished.
Refer to these materials I made for this purpose on page “Multiframe Synchronization”.
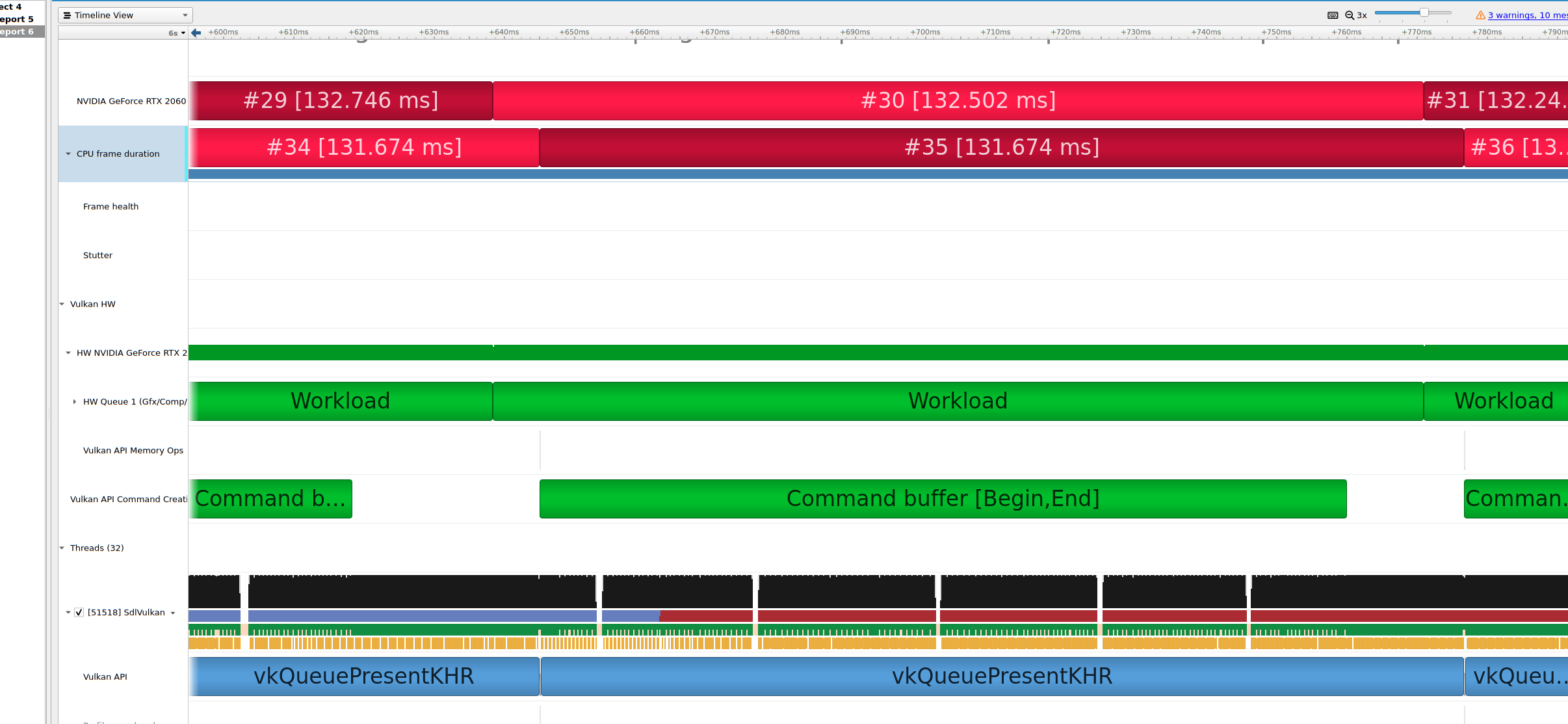
I am not entirely sure if I am interpreting the charts from the tool correctly. It seems that while the GPU is still chewing on frame nr. 30 the CPU is already working on frame nr. 35. That should not be happening if you set a sane frame-in-flight limit (i.e. 2, or 3 maximum). PS: for the purposes of trying to figure out what is happening, you might even want to set it to 1.
Thanks a lot for clarification, I will definitely have a closer look at the slides and revisit my loop logic.
I can explain the frame pre-recording you mentioned. I have meanwhile reduced it to “1 in advance”. That was essentially my approach to having a command buffer prefilled in a separate thread and taking the CPU cost out of the draw loop.
The unexpected thing is that when I keep things in a single thread I get the same number of frame rates with the same saturation of the HW Queue when profiling (as I did earlier today). I hope to find an explanation by revisiting my synchronization because every resource I have seen it was pretty much claimed that the GPU could not be busy without threaded command buffer building. Now I don’t know, is that the wrong assumption, or is it something else like the multiframe synchronization. After all commandbuffer building should not cost anything in terms of GPU I always thought, so that doesn’t leave too much room for possibilities…
That gets us to the beginning. Why do you preassume any framerate benefits? If your GPU is already fully fed, and the CPU work does not even saturate a single CPU core, then it would not matter in any which way you cut and process the CPU work, would it?
every resource I have seen it was pretty much claimed that the GPU could not be busy without threaded command buffer building
Then every resource is wrong. You can saturate GPU even with no command buffer building at all (i.e. just spam the same prebuilt command buffer million times).
PS: spreading CPU work has its uses, such as cutting down latency. But since your stuff takes 130 ms on GPU, that is very much secondary concern since you are already like 10 frames late.
sure, the “trivial” case is not lost on me - a while loop thread will also busy the cpu. it’s just that before profiling I could only see an overall time and, initially, the burden was on the command buffer building part, so to try to optimize there is not an unreasonable thing to do.
I did jump to the wrong conclusion, I suppose the information that led me there was more so that the GPU is generally doing its work faster than it can be fed, from which I thought I would need threads to keep it busy.
Anyhow, I’ll do some more checking, and then probably try other avenues of optimization that sound fun, based on more algorithmic smarts, like frustum culling, etc.