My use-case is fairly straight forward. I need to create a collection of images, each image and the data that goes into creating it is entirely independent of the other images. I am using SkiaSharp to connect through to EGL and OpenGL.
I make sure to create the EGL context in an independent worker thread, and from that thread I create a pbuffer that I use to generate bitmaps. It all works fine, but when I monitor the throughput I can see that the GPU is being utilitized at most 40%.
Ideally I’d like to parallelize the generation of the images so that the throughput is optimized and the GPU utilization is increased.
In each of two threads I do the following:
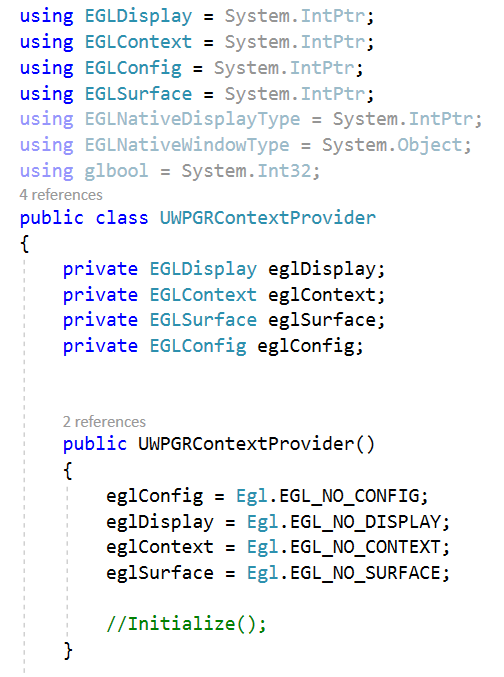
Generate an EGLDisplay (eglGetDisplay, eglInitialize)
Choose a configuration (eglChooseConfig)
Create an off-screen Rendering area (eglCreatePbufferSurface)
Create a rendering context (eglCreateContext)
Make the EGLContext current (eglMakeCurrent)
I then create a GRContext in Skia in the hosting thread so that SkiaSharp can reference the EGLContext.
When I run the app using two threads, each will generate valid contexts and surfaces, but when I have both threads issuing instructions OpenGL commands I get memory violations.
Am I correct in understanding that as long as in each thread an independent context is generated, an independent surface is created, and the context is made current and no state is shared with another thread doing the same thing, that the OpenGL calls will not affect each other?
I’ve hit a bit of a dead end with this. Any insights would be greatly appreciated.
Ok, so each is generated on a different CPU core and rendered by a completely different GPU? … I think you see where I’m going with this.
Ok. Where?
Generally, yes. But keep in mind that these are all funneling down and beating on the same GPU (assuming a 1 GPU system). So you have to have the GPU memory required to support the sum total GPU memory needs across all of the tasks. Also, your rendering perf is going to be split across these tasks.
Parallelizing can help in some circumstances where you are CPU limited, but it doesn’t gain you a free GPU. Also, you end up with the overhead of context swapping when you have multiple GL threads trying to make use of the same GPU at the same time.
Generally what’s recommended (for single GPU) is to offload CPU-heavy processing to other CPU threads, and have a single CPU thread that is responsible for issuing all of the rendering work to the GPU.
Thanks for the explanation. The issue is that the GPU never gets higher than approaching 40% of its utilitization capacity when I generate the bitmaps in one thread. If I try two threads as I’ve described above I get memory violations. The contexts don’t share any state, so I’m scratching my head about what is happening.
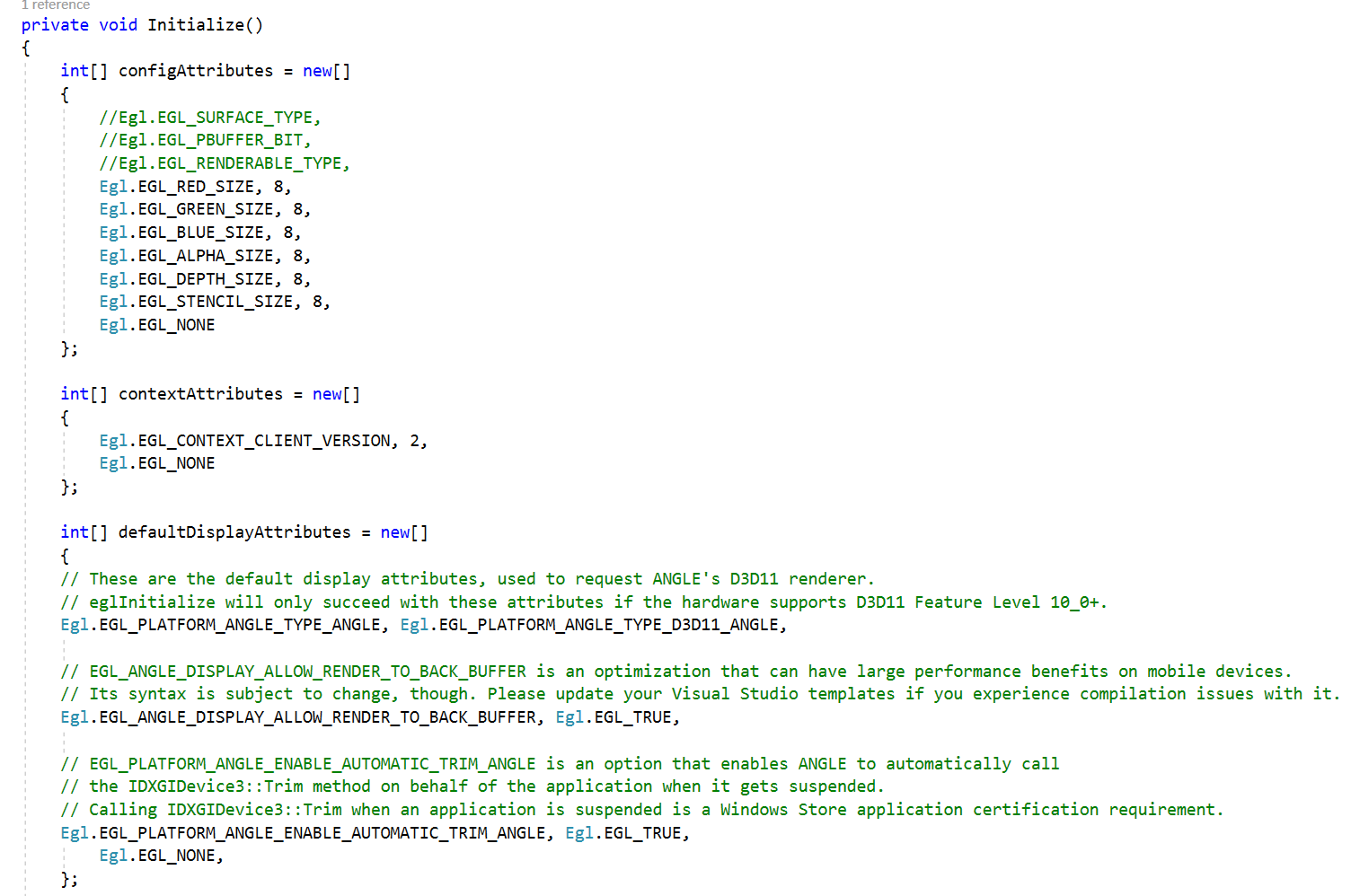
Above is the code that I am using. I call CreateGRContext in a background thread.
Is there anything apparent which I’m doing incorrectly? I don’t know much about the actual implementation of how the buffers are managed. Is there something I’m doing wrong with the config attributes?
You know, you can just post the source code inside a pair of of ``` tags (each on their own line), and the forum software will format it for you. For example:
// Bind the framebuffer
glBindFramebuffer(GL_FRAMEBUFFER, frameBuffer);
// Set the texture unit the shader should read from
glUniform1i(samplerUniform, 0);
From your code above, it appears that:
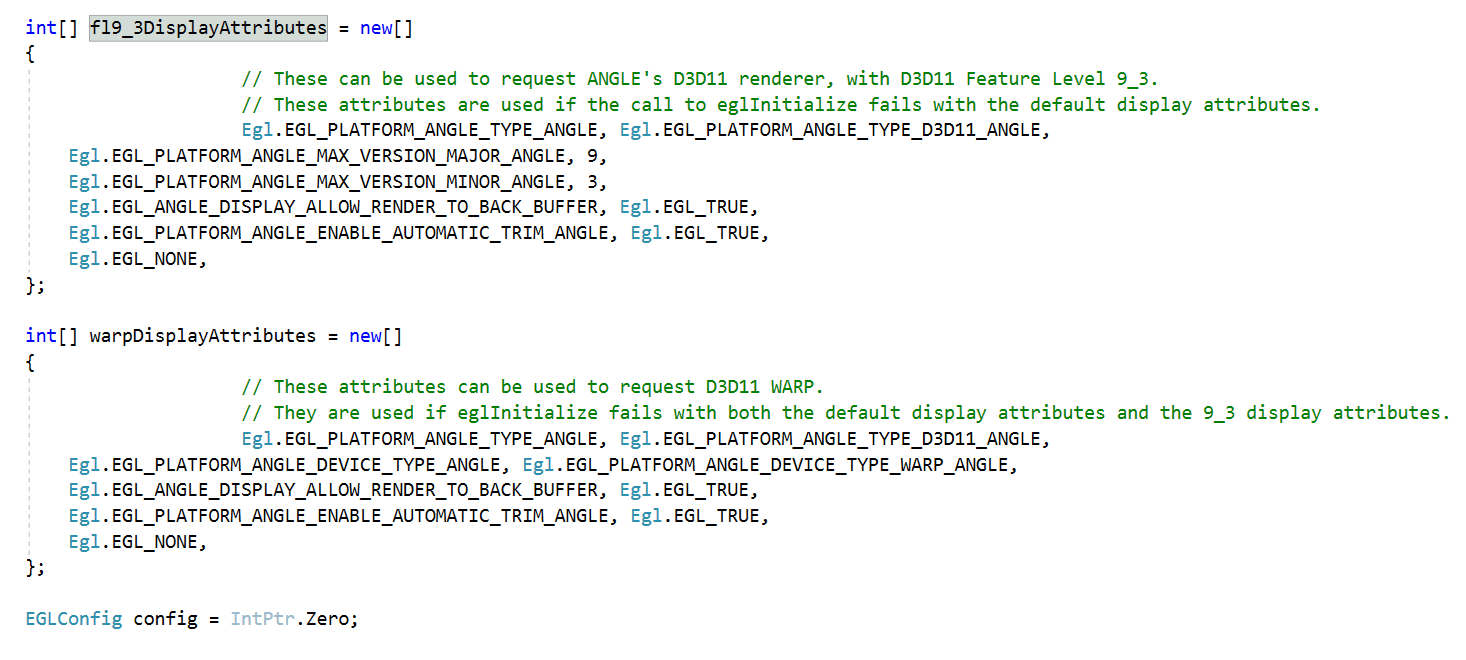
You are trying to render through an OpenGL ES -to- Direct3D conversion shim (ANGLE) on Windows, and
You may be requesting that ANGLE not even make use of the GPU but instead make use of a CPU software rasterizer (EGL_PLATFORM_ANGLE_DEVICE_TYPE_WARP_ANGLE; see ANGLE_platform_angle_d3d).
With either of these in-play, you probably shouldn’t expect to max out the performance of your GPU.
Also, do you have VSync disabled? I don’t see a call to eglSwapInterval
Yes, you mentioned that. What you didn’t answer was my question about where. I would check with the ANGLE docs and forums to make sure that what you’re trying to do is even supported by ANGLE. If so, run your app through a memory debugger to get some insights as to where things might be going awry.
Thanks for helping me to understand all of this better. I don’t know much about Angle (I got the settings on line from a Window app that works) but I can confirm with the debugger that the GetPlatformDisplayEXT call is successful using the defulatDisplayAttributes, so the EGL_PLATFORM_ANGLE_DEVICE_TYPE_WARP_ANGLE is not passed in as part of the configuration request.
I also made sure the VSync was disabled, by adding these lines:
if (Egl.eglSwapInterval(eglDisplay, 0) == Egl.EGL_FALSE)
{
var errorCode = Egl.eglGetError();
throw new Exception("Failed to get Control swapping in EGL display");
}
With the debugger I can verify that the setting of the interval was successful.
I have a log which lists the calls to the openGL which I’ll put in the next message. It shows that both surfaces appear to generate the same way.
The memory violation happens on the first call to Skia’s DrawPath (sorry I don’t have the breakdown of what that maps to in OpenGL). That is the very first thing that either thread does: both just generate a random sequence of polygons.
I know that this may not be of any help (and may be a shortcoming of Skia???).
Thanks again for your help. I know a fair few people have been trying to do the same thing.
Given where the crash is occurring, you’re probably more likely to get useful tips by posting about your problem in a SkiSharp forum. It’s not really sounding like this is an OpenGL ES issue.
Here are a few threads that describe symptoms similar to yours. The causes may not be the same, but they could give you some ideas:
Thanks so much for your help. I don’t hold onto the SKCanvas object, so that is not the problem. Also, the SkiaSharp forum is where I started with all of this, months ago. The developer of SkiaSharp is also actively querying the Skia team (see Redirecting to Google Groups) without hearing anything back. It is good to know that the setup of the EGL matches how you think it should go, so it must be something in the way that SkiaSharp / Skia calls into the library.
I will keep querying the forum, and in the worst case, use CPU rendering instead.