Well, at least on current nvidia driver.
I made simple test program to gauge performance for both APIs (and dx9 for comparison).
It runs two different tests in succession, first one draws 20,000 of small quads to measure API call overhead, and second one draws Julia Set on a large quad of (somewhat animating) 125,000 triangles, to test shader execution performance.
Those look like this:
Here are source code and binaries for those interested.
[Src] https://drive.google.com/open?id=0BzeNJCHJJEyjUTZDTmF6andRZUE
[Bin] https://drive.google.com/open?id=0BzeNJCHJJEyjeDVURWlTaWVBNWM
You will probably need Visual Studio 2015 redistributable package to run the .exe.
If you want to compile the project, you should have Visual Studio 2015, LodePNG and Vulkan SDK.
I also used VLD, but you can disable it by simply commenting out “#include <vld.h>” in WinMain.cpp.
(Sorry for lack of active links, this board doesn’t allow me to link too many urls.)
Anyway, for julia set rendering, performance of both APIs are almost identical as expected.
But it wasn’t the case for the heavy draw call test.
With multithreading off, both APIs shows similar performance (about 300fps) on my system (i7 4770, geforce 980 GTX).
But with MT on, dx12 runs at 600fps but in vk it’s still the same 300fps, no performance gain whatsoever.
The problem is, even though both renderers were running at same 300fps in ST, GPU usage for dx12 was only 50%, while in vk it was well over 90%.
dx12 runs only at 300fps in this setup because of cpu bottleneck, busy to record and submit commands in ST, while in vk’s case it was already in gpu bottleneck situation, despite shader workload is minimum.
Hence, as soon as cpu bottleneck is alleviated by MT, dx12 shows huge performance leap while vk shows none.
I ran various setup(batch count, quad size, different shaders) and profilers to understand this situation.
And my conclusion is this:
vk can record and submit rendering commands very fast, even faster than dx12.
But for whatever reason, it has to impose heavier workload on gpu than dx12 for each API call.
As a result, with MT off, if you artificially setup the test for cpu bottleneck, by increasing batch count and reducing quad size, vk runs faster than dx12.
But if you make it more gpu intensive, by increasing quad size or with more complex pixel shader, dx12 quickly outperforms vk.
With MT on, dx12 runs always faster than vk, sometimes more than twice.
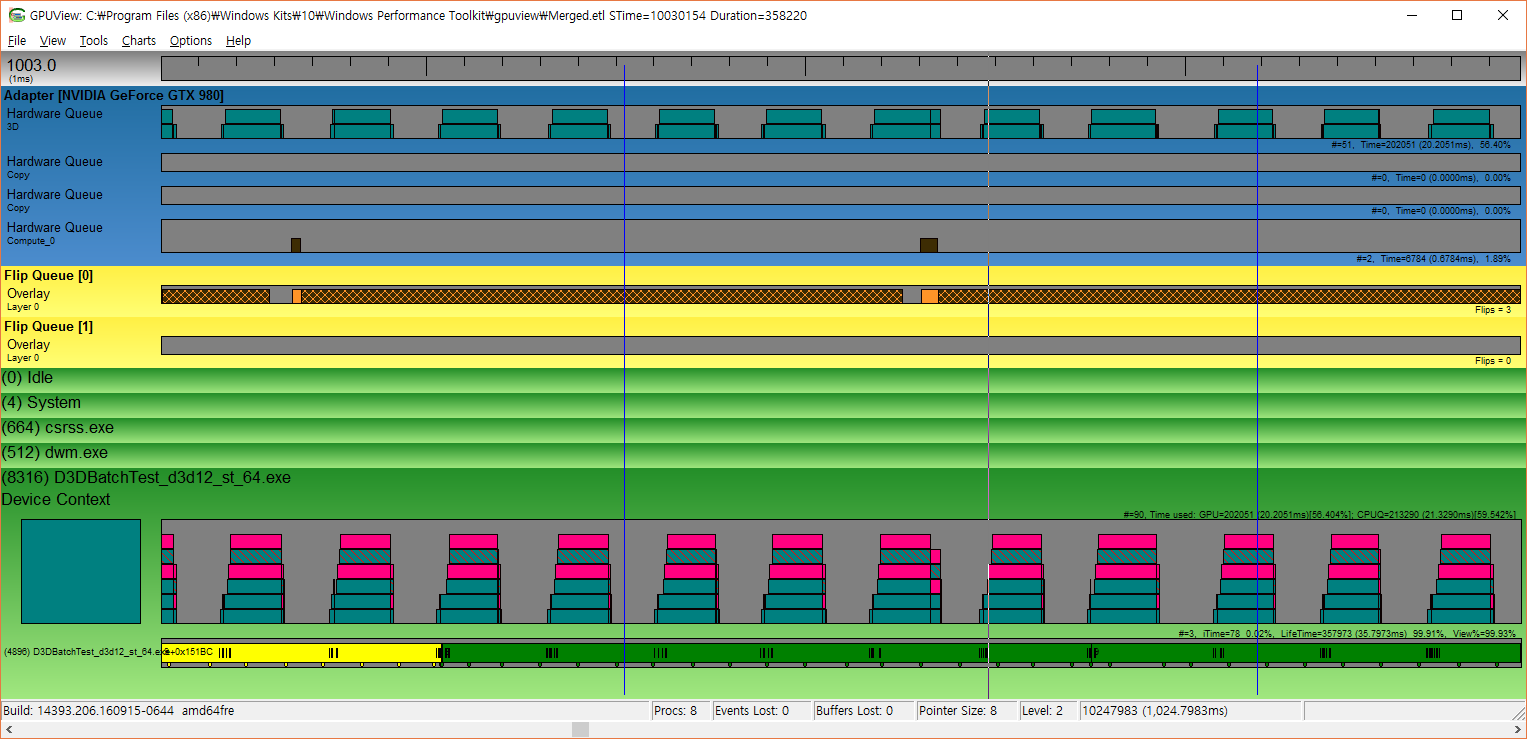
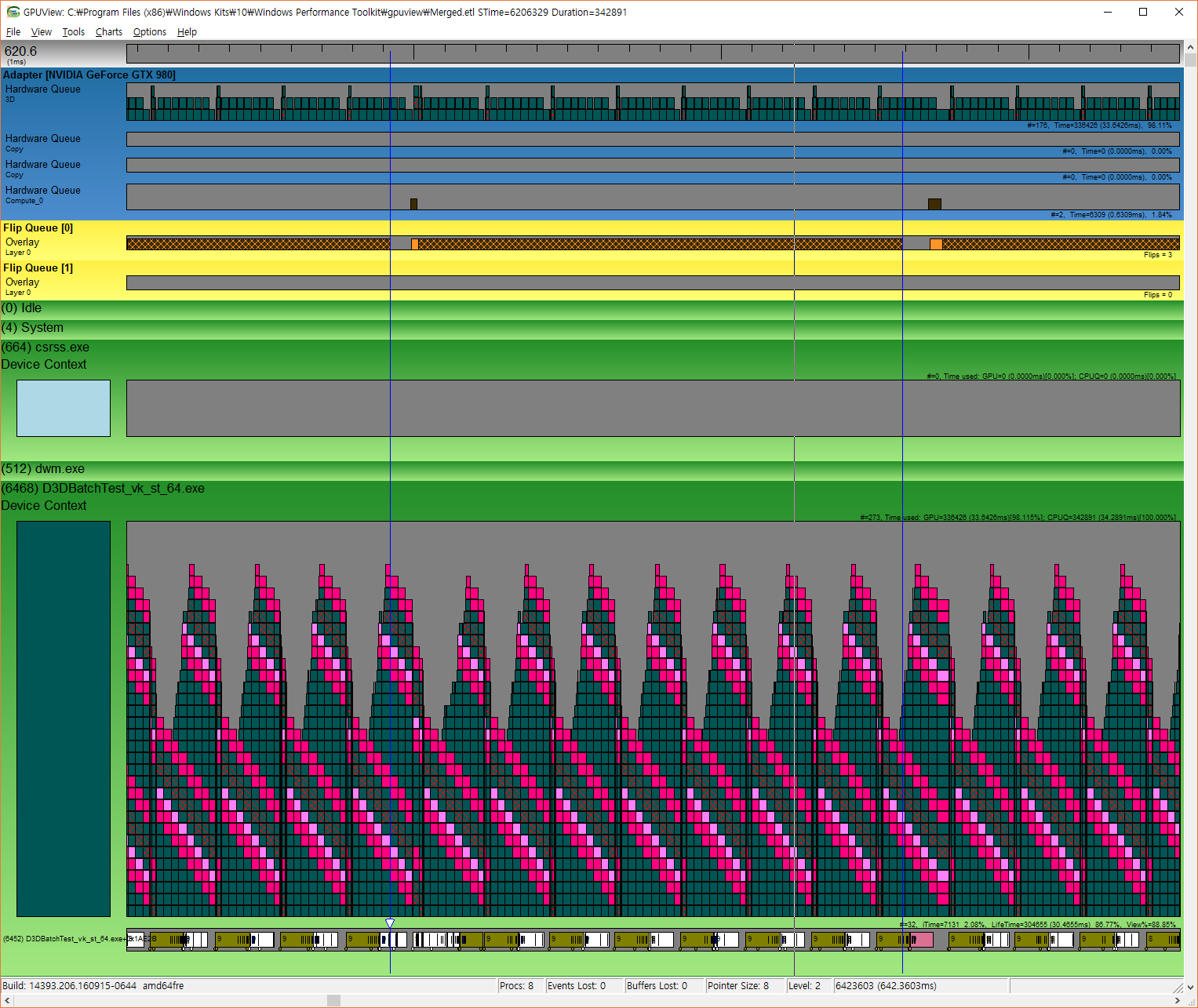
Microsoft’s GPUView also shows different characteristics of drivers for both APIs.
First one shows dx12 trace of drawing 8,000 batches, second is vk with same setup.
In “Hardware Queue” section, you can see small boxes stacked up.
Each one of those boxes is “command packet”, it is stream of api commands which driver sends to hardware for execution.
See wide horizontal blank spacing in dx12 trace, that’s gpu idle time and vk trace doesn’t have those.
There’s a difference of box dispostion too, in vk trace boxes are much smaller, and many.
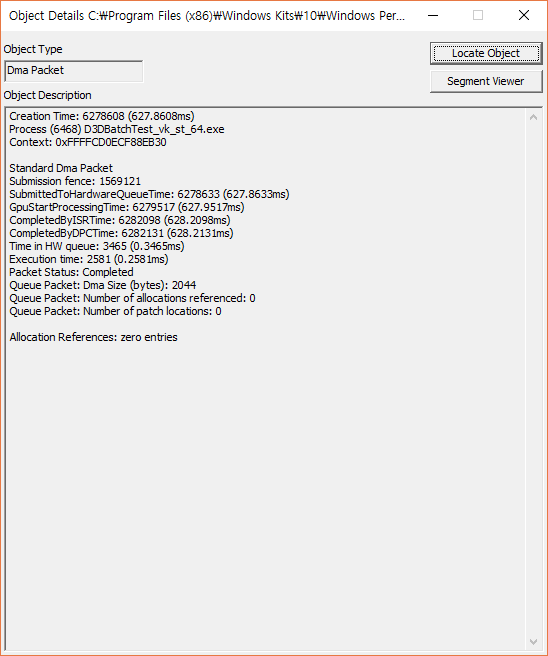
If you click one of those boxes you can see basic information of that particular command packet.
Regardless of batch count setup, in dx12 command packet is uniform 32k bytes, while in vk it is rather small, and various in size (~2044 bytes).
If this information is accurate, it means dx12 driver batches commands in large uniform packet, while vk driver behave somewhat differently.
Whatever it does differently to dx12 driver, it doesn’t look very effective.
Honestly I don’t understand why drivers for both apis have to behave so differently with significant performance gap, because to me both apis look damn close to each other.
Yes, this test is a extreme case and real world games won’t exibit this much performance differences.
But bottom line is, workload on gpu per api call is always higher in vk than dx12. And in today’s games, thousands of draw calls per frame is common.
Extra cpu overhead in dx12 can be mitigated by MT, but there’s no such option for extra gpu overhead in vk.
That’s somewhat disappointing as a developer who plans to implement new engine based on vulkan.
I’ll probably stick to vulkan because of it’s multiplatform nature and in my opinion it’s a bit cleaner api than dx12.
So hopefully future driver update will fix this issue.
I also like to know the situation on AMD gpus.
So feel free to download the test program and leave some feedbacks.
Thank you.