I am the author of the supermodel emulator. Our users have informed us that the latest nvidia driver breaks our rendering engine. Previous driver versions all worked fine. The code also runs fine on AMD cards and intel cards.
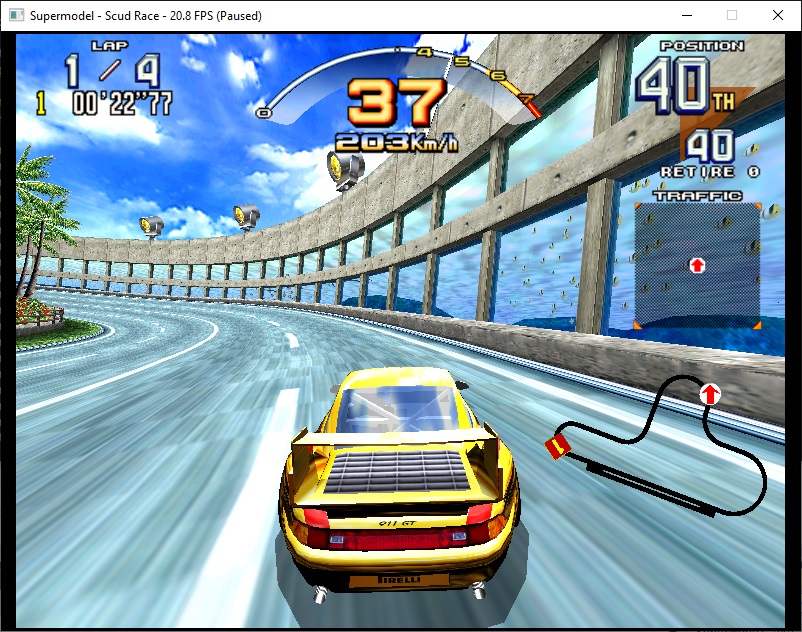
Artifacts are appearing all over the place (water and road). The game uses different textures for different LODs to emulate a water effect. Something similar happens on the road so the artifacts are more visible.
Which is standard code to calculate the LOD. I thought there could have been a problem with the partial derivative calculation so I swapped to the internal method of textureQueryLod(texSampler,texCoord)
But the results are identical.
If i force the lowest texture value by returning 0 everything looks as expected (besides the aliasing). Ie there is no problem with the texture coordinates themselves.
I actually have 2 shader paths for this code. One which renders triangles and this one works fine. And a second version that natively draws quads by passing gl_line_adjancy to a geometry shader and then outputting 2 triangles. The texture coordinates and other attributes are calculated in the fragment shader, rather than doing normal interpolation. Anyway it’s this second version which fails with the new drivers. But otherwise the shaders are identical.
Which begs the question: why do you think this in particular is breaking?
Since you get the same results, it would seem either both of these are broken, …or neither are broken and the problem (or problems) lie elsewhere. Maybe I’m missing something?
A few ideas for you:
First, when comparing 441.41 with the previous driver, have either you or your users verified that all of the settings in NVidia Settings → Manage 3D Settings which are common to both drivers are set exactly the same? In particular, those settings related to Texture Filtering.
Second, I notice in the 441.41 Release Notes that OpenGL and Vulkan support for the Image Sharpening Gizmo (other link) was added (previously, it was D3D only). Have you verified that it is nailed off in 441.41, or tried tweaking that to see if it has any bearing on your problem? I haven’t looked into it, but it sounds like it might be doing some LOD bias tricks.
Third, have you looked for any other new settings in the Manage 3D Settings dialog in the 441.41 driver?
(Also I’m assuming neither you nor your users have app-specific overrides to the 3D settings set in NVidia Settings for your app.)
Finally, when you install 441.41 (and the prior driver), have you tried doing a Clean Install (it’s a checkbox in the installer IIRC)? It’s rare, but every long once in a while I find that I need to do this when installing a new NVidia driver version.
I checked and the image sharpening options were all off by default.
The only thing I can think of is the partial derivative calculation must be broken for the edge pixels. I’m not 100% sure how the partial derivative calculation works. The literature says it takes the value from the adjacent pixel, and the h/w renders 2x2 pixel blocks. How does that work with say, a line of 1 pixel thickness?
It also says that if they are called for a conditional block the results can be undefined. There is branching in the quad shader to calculate the actual texture coordinates. But there is no branching in calling the derivative function.
That’s my understanding. If you bring up the GLSL Spec and search for “derivative” and “helper”, you can get a bit more insight. Basically, in the absence of required shader invocations next to a fragment, “helper invocations” may be launched in parallel for neighboring fragments to help generate fragment-to-fragment deltas (derivatives) for those edge fragments.
As far as I know, how all this works with different GPUs and drivers is implementation-specific. From the GLSL spec:
Right. So just as you’re doing, it’s my understanding that this is fine so long as the derivative calc is outside of the conditional logic.
You know, while helper invocations themselves can’t cause side-effects via the framebuffer or GPU memory, you might be able to use cross-fragment communication tricks with gl_HelperInvocation to see if a “visible” fragment’s derivatives were partially computed though the aid of one or more helper invocations. That might give you a bit of insight on those edge pixels.
Something else you might check: does the appearance of the problem correlate with specific texture settings for aniso and/or min/mag filter?
Everything else is done in the shader. It’s just simple mipmapping which is fairly trivial to implement. But the hardware I am emulating uses a different wrapping mode which is like a combination of GL_CLAMP_TO_EDGE and GL_REPEAT. This can only be emulated in a shader really.
It’s essentially identical render code, other than the attribute interpolation. The actual texturing is identical. I am pretty stumped on this problem really. Other than some kind of driver regression I am not sure what it could be.
I didn’t have the time to thoroughly analyse your code. However, a couple of points:
If you’re performing texture filtering and wrapping yourself, texelFetch is probably the way to go. You should be able to get the same result with textureLod and nearest-neighbour filtering, but texelFetch is less likely to have issues arising from driver-based “tweaks”.
Given that you’re passing per-quad data into the fragment shader, you could just derive closed-form expressions for the derivatives and evaluate them, rather than relying upon the (implementation-dependent) finite differences used by dFdx and dFdy.
Texelfetch maybe better but the problem is before that, the actual LOD calculation fails.
I’ll try drawing the LODs as different colours and it might make the problem clearer
The values are undefined for many of the edges of polygons. Strangely you can see the quad outlines, so only the outlines of the quads are undefined … The internal triangles have valid edges.
Interesting. So I think you’re saying that mml is < -1e6 for these QUAD-edge pixels, correct (possibly -Inf)?
This would this seem to suggest that delta_max_sqr is probably zero (or an insanely small positive number, or negative). Which suggests the texcoord derivs may be zero. Which would indicate that possibly there’s no change in the texcoord between the edge of the quads and the “helper invocations” launched just outside the quad.
You said:
How are you computing those texture coordinates?
Is it possible their values are “clamped” at the edge of the quad primitive? …possibly only in the GL_LINES_ADJACENCY → GL_TRIANGLE_STRIPS case?
I didn’t explicitly check but pretty sure they are infinity.
Yes this is what I suspect. The issue is, how does the hardware calculate these extra invisible pixels? Because technically they are outside of the polygon.
Well … the short answer is I pass the vertex attribs for each of the 4 vertices of the quad to the fragment shader and calculate them based upon area and distance etc. The algorithm is here
No they aren’t clamped at all. The mipmap calculation is also done before the texture coordinates are wrapped/mirrored etc. It worked perfectly before before the driver update.
Given gl_Position.xyw (Z doesn’t matter here) for the three vertices of a triangle, you get a projective mapping from barycentric coordinates to screen coordinates. This can be inverted to give a projective mapping from screen coordinates to barycentric coordinates, which can then be used to calculate the remaining attributes for any screen position. The mapping covers the plane of the triangle; the triangle itself is the region for which all three barycentric coordinates are non-negative, but the mapping doesn’t care whether you’re interpolating or extrapolating; the calculation is the same either way.
When it comes to rasterisation, the hardware just needs to dilate (enlarge) the set of generated fragments by one pixel in each direction in order to be able to calculate partial derivatives. Calculation of fragment shader inputs proceeds without regard to whether the fragment is inside the triangle.
Hard to say. If it’s a bug in the compiler, refactoring the code may avoid triggering it. Also: is there anything interesting in the output of glGetShaderInfoLog or glGetProgramInfoLog? These can include warnings even if compilation and linking is successful.
Version 1 of the frag shader code has a discard for fragments that are outside of the quad.
There’s no discard in the version of the code that you’re using there, is there? That would definitely cause problems with derivative computation on the edges of your quads.
Also, in at least one of the versions, some of the fragment inputs have been changed to be noperspective so that interpolation occurs linearly in screen-space. From the form of the above, I’m assuming you are not calling dFdx() and dFdy() on the screen-space-interpolated texcoord input directly, but rather interpolating the noperspective values for this fragment of the quad (interp_texCoordOverW, interp_oneOverW), applying the perspective correction (dividing by interp_oneOverW), and then calling dFdx() and dFdy) on that perspective-correct texcoord. Is this correct?
Finally, just something I noticed. In one of the versions of the geom shader, it appears that the color and oneOverW interpolators have been declared with flat interpolation. This doesn’t seem right since the gl_Position.w can vary across the verts in a quad. This would tend to make at least the denominator of interp_texCoordOverW / interp_oneOverW constant across all quad fragments, possibly helping contribute to 0 derivatives. That said, I seriously doubt the texcoord interpolator (numerator) was declared flat, or you couldn’t be getting the results you are. And even so, I think in the case of mismatched qualifiers, it uses the ones in the fragment shader, which it looks like are all noperspective.
The fragment shader executes a discard if the weights have different signs (line 280; commented with “need to revisit this”). It would definitely be worth seeing what happens without that. It also executes a discard for transparent pixels, but the one for the weights seems a more likely candidate. I haven’t analysed the weight calculations thoroughly, but I wouldn’t be surprised if these are negative for points which lie outside of the quad.
In the code linked in the OP, oneOverW is (like most of the fragment shader inputs) a flat-qualified 4-element array, i.e. the geometry shader just passes the four per-vertex values directly to the fragment shader which does its own interpolation. Only v and area are interpolated (in screen space); these are then used to calculate the interpolation weights for the other values.
Ah! Thanks for noticing that! I looked up in the thread for the GLSL earlier, and not seeing it, thought he hadn’t posted more than that tiny snippet above. I’d forgotten that he’d posted links to .H files with the GLSL embedded in C++ strings. Those sources answer several questions, and confirm those concerns I had.
It also answers this question I had:
The answer to this question I asked is “yes”, …except that the texCoord and oneOverW varyings are not being interpolated with noperspective as I suspect they should be, but rather are being qualified as flat.
Hi guys, thanks for the detailed look at this. The flat attribute interpolation is correct. Each pixel in the fragment shader gets a copy of the vertex attributes for each of the 4 vertices that make up the quad. There is nothing to interpolate because each pixel gets the same values. The formula calculates the interpolation between the 4 vertices based upon the interpolated lengths and areas.
I’ll try without the discard. It’s possible it’s causing the pixels outside the quad to not draw but i haven’t explicitly checked the maths.
The discard allows us to draw complex non-planar quads that could potentially could only be drawn with thousands of triangles. I actually really like the solution, but I’ve bumped into all kinds of hardware and driver bugs trying to get it to work. On older amd drivers they didn’t support interpolation qualifiers for the data coming out of the geometry shader which meant it didn’t work at all. And passing 4x the amount vertex attributed you run out of space fast.



{kind=link}