I know that shadow mapping is a common problem on forums but this time I couldn’t find the answer to my problem.
I set up an FBO and a depth-component texture correctly and render my scene from my light’s point of view to this FBO. Later I wanted to use this texture in a fragment shader but the values in this are always between 0 and 1. Somewhere I read that GL_DEPTH_COMPONENT-type texture values are clamped but isn’t there a function to disable this? Or should I use a different component-type (like GL_R32)?
Of course they have to be between them but I thought that zero represents the near z plane and one represents the far z plane. But in this case the clamping was done on world-space distances so the depth-texture “can’t see” further than one world unit. If I render a scene where the objects are two units far away from the light then the texture will contain only 1.0 values.
Those values are in normal coordinates after your projection, so if your zNear is 10 and zFar is 1000, something like 10 would be zero in the depth texture and something at 1000 would be one in your depth texture.
It’s perfectly legitimate to go between those spaces. In shadow mapping, you’re taking a point in world or camera space and moving it into your “depth map” space, which would also have a value between zero and one for the comparison.
But in this case the clamping was done on world-space distances so the depth-texture “can’t see” further than one world unit.
No! Definitely not! You don’t store world-space depth values in a depth map. You store window-space depth values (typically), which are 0…1 and represent the entire depth range for the entire light-space frustum (i.e. the region between the light-space near and far clip planes)!
For a little more context, NDC-space depth values are within -1…1 for depth values within the light frustum (of course, always are). glDepthRange is typically 0,1, which means the resulting window-space depth values are 0…1 when you’re rendering your shadow map. And “that” is what gets stuffed in your shadow map (i.e. depth map).
Sorry for the late reply and thanks for all the answers.
Now I remember that the OpenGL uses reciprocal depth storage and comparison but what I couldn’t puzzle out is how does it calculate the z-values before storing them in a floating-point texture. If I knew the formula then I could decipher the inverse operation to calculate the linear value but I couldn’t find this equation.
(I tried the “return (2.0 * n) / (f + n - z * (f - n))” formula from the geeks3d.com page but I would like to know how does the “non-linearisation” (and thus the linearisation) work and not just implement it anyway.)
Is there a place in the OpenGL documentation where the z calculation is written down?
Re the geeks3d formula, looking at it a bit, it doesn’t feel right. Plug in z_win=1 and you do get 1, but plug in z_win=0 and you just get a mess (not 0, which you’d expect).
…but I would like to know how does the “non-linearisation” (and thus the linearisation) work and not just implement it anyway.)
Is there a place in the OpenGL documentation where the z calculation is written down?
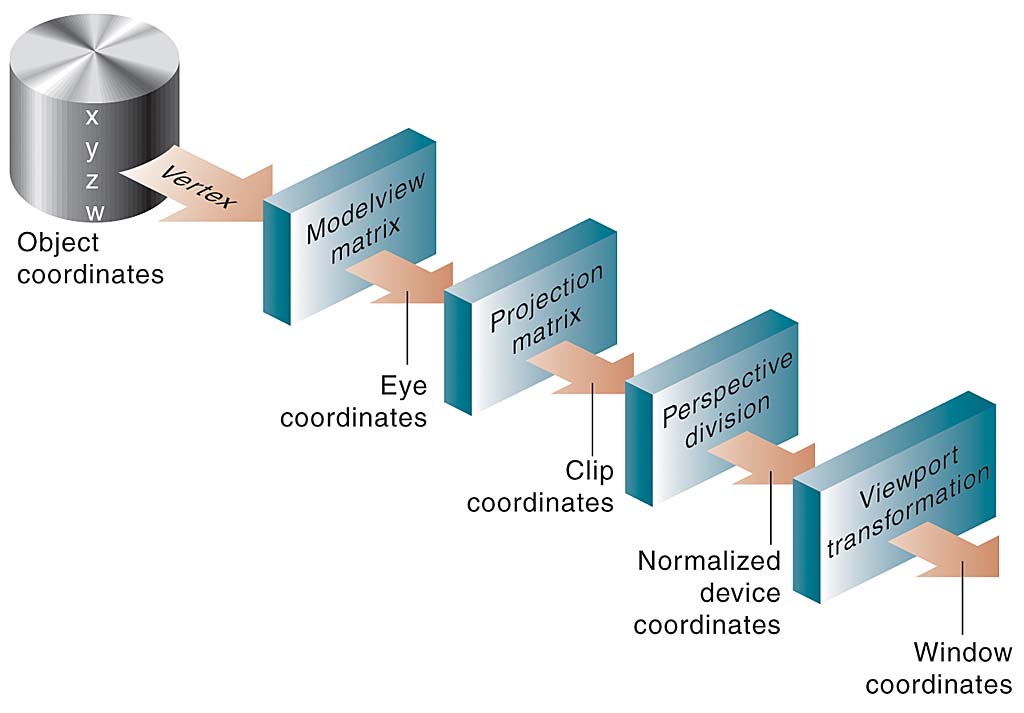
Sure. You know what the PROJECTION transform is, right? Takes eye-space to clip-space. Do the perspective divide and you have NDC-space. Then just scale and shift that and you have window-space.
The main thing you need is the PROJECTION transform. Look at Appendix F in the Red Book:
At the bottom of the page are the perspective and orthographic projection matricies. All you need are the bottom two rows to compute z_clip and w_clip from z_eye (w_eye == 1). Then just divide z_clip/w_clip, and you have z_ndc. Then shift and scale that -1…1 value into 0…1 (*.5+.5, assuming glDepthRange 0,1) to get window-space Z. You can write all this out. It’s not complex. That’ll give you an expression that defines z_win in terms of z_eye. This defines the normal Z transform, and what you call “non-linearizing” it.
Then given z_win, you want to “re-linearize” it. So you want something like z_eye, but in 0…1 range. In other words you want to take the previous equation, solve for z_eye in terms of z_win, then plug that into (-z_eye-n)/(f-n) to get a linear-in-eye-space 0…1 Z value in terms of the window-space Z value.
I wanted to ask which direction is better (converting the depth texture values to world space or converting the in-world distances to the texture’s window space) but maybe the first method needs less extra calculations in the case of a cube map texture.
I don’t understand the question. They produce two different things, not the same thing via two different methods.
Also beware anytime you’re thinking of working with “world space” in a shader. In general, world space may be bigger than can be represented with sufficient accuracy in a shader with single-precision floats (if not now, then maybe in your app in the future), and you may screw your current (or future) self by doing stuff with world space in the shader. Use object, eye, clip, NDC spaces, but avoid world like crazy.
What are you trying to do again? There’s probably another way to do it.
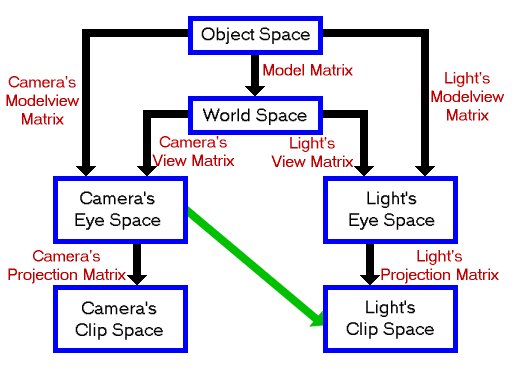
He’s talking about shadow mapping. The depth comparison should generally give the same result in either space. Though I suppose he means eye space, not world space.
Ah, OK. Well maybe I’m missing something obvious, but here’s the thing: to do the shadow map lookup, you need to project your position into light space to get your shadow map texture coordinates. So seems to me it’d be needless added work to take the depth (in light space) that you get back from the lookup and back it all the way back out to eye-space to do the comparison, rather than just do the comparison in light space since you’re there already…