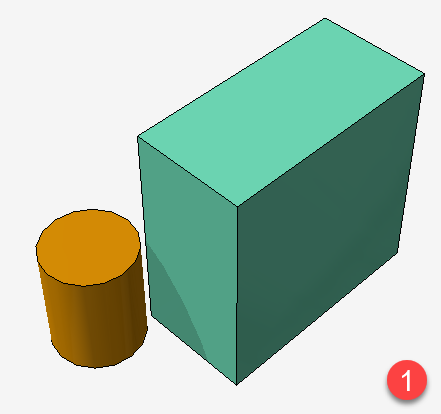
The result is a completely messed up shadows on the roto-translated object itself.
I cannot understand where the problem is and if we can fix it. Is it possible that during the first pass drawing, with the camera on the directional light position, the object is roto-translated to a wrong position compared to what happens in the second pass with the actual scene camera?
Are you applying the same transformation for both passes?
Are you applying the transformation to the model-view matrix (in both cases)?
In the second pass, you have to transform the vertices to both the light space (to determine the coordinates for the shadow map lookup) and the camera space; is the transformation being applied to both?
Is the transformation being taken into account when computing the bounds of the shadow map? Or is it pushing the object outside of those bounds?
Are you applying the same transformation for both passes?
Yes, as you can see in the pseudocode below.
Are you applying the transformation to the model-view matrix (in both cases)?
Yes, as you can see in the pseudocode below.
In the second pass, you have to transform the vertices to both the light space (to determine the coordinates for the shadow map lookup) and the camera space; is the transformation being applied to both?
I’m not sure about this. I’m only doing what you see in the pseudocode below. Maybe this is my problem?
Is the transformation being taken into account when computing the bounds of the shadow map? Or is it pushing the object outside of those bounds?
I’m not sure about this. I’m only doing what you see in the pseudocode below. Maybe this is my problem?
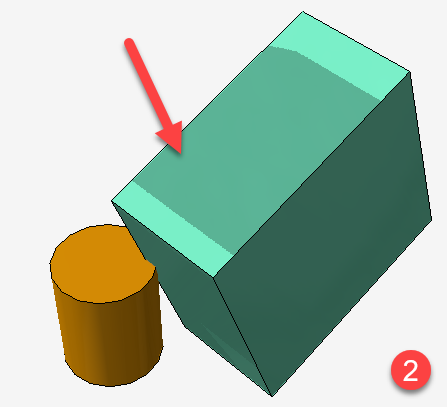
Nothing in the pseudo-code stands out. From the bottom image, it appears that the shadow map is rendered using the transformed cube but the lookup is being performed with the un-transformed coordinates. IOW:
It appears that the transformation is only applied to the camera-space coordinates, and not the light-space coordinates.
Also: you should try to get a single shadow map working before progressing to cascaded (parallel-split) shadow maps.
That article assumes you know how shadow mapping works. Note the mentions of “light’s view-projection transformation matrix” (or transform), textureMatrix, texScaleBiasMatrix, etc.
For a decent overview on how this works, see the diagram and description in the Projective Texturing section here:
One you understand it though, just pass the matrices into your render-pass GLSL shaders as you would any other matrices. Ignore the mentions of the old GL fixed-function texture coord generation method of doing the same – e.g. glTexGen*(), EYE_LINEAR, etc.