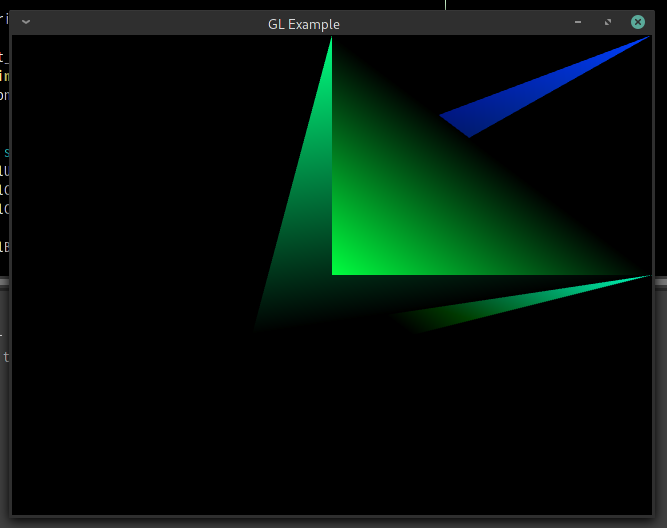
In the process of trying to fix some errors I realised I was still understanding the vertex array id wrong, it just happened to work because I was only linking to one cache of floats (gave up trying to keep them all in one buffer for time being), if my understanding is finally correct then each vertex array is only supposed to hold 1 buffer of floats and as many index buffers as one pleases (within memory limits obviously), this kind of information would be helpful in the guides but not a single one mentions that, as if they expect people to figure that out without any help (despite the fact they’re consulting a guide in the 1st place).
Anyways I’ve currently switched to a paired cache buffer & index buffer system but opengl is now throwing errors at me when I mainly just moved code to a more appropriate place for this system. Here’s the code block that’s throwing errors:
for ( uint strip = 0; strip < Strips->used; ++strip )
{
STRIP *Strip = strips + strip;
BUFF *traits = Strip->Traits;
uint used = traits->used;
for ( uint trait = 0; trait < TRAIT_COUNT; ++trait )
{
BUFF *Trait = traits + trait;
BUFF *Cache = Caches + Traits->UseCache[trait];
uint values = Traits->PerTrait[trait];
uint TraitID = Traits->TraitIDs[trait];
uint CacheID = Traits->CacheIDs[trait];
uint IndexID = Traits->IndexIDs[trait];
uint location = Core->TraitLoc[trait];
if ( trait != TRAIT_PLACE && trait != TRAIT_COLOR )
continue;
glX( NULL, glEnableVertexAttribArray( location ));
#ifdef _DEBUG
fprintf
(
errout,
"model = %u, trait = %u, Cache->size = %zu\n",
model,
trait,
Cache->size
);
#endif
glX( NULL, glBindVertexArray( TraitID ) );
//glX( NULL, glInvalidateBufferData( CacheID ) );
glX( NULL, glBindBuffer( GL_ARRAY_BUFFER, CacheID ) );
glX( NULL, glBufferData
(
GL_ARRAY_BUFFER,
Cache->size,
Cache->addr,
GL_DYNAMIC_DRAW
) );
glX( NULL, glVertexAttribPointer
(
location,
values,
GL_FLOAT,
GL_FALSE,
0,
NULL
));
glX( NULL, glBindBuffer( GL_ELEMENT_ARRAY_BUFFER, IndexID ) );
glX( NULL, glBufferData
(
GL_ELEMENT_ARRAY_BUFFER,
used * sizeof(uint),
Trait->addr,
GL_DYNAMIC_DRAW
));
}
glX( NULL, glDrawElements( Strip->DrawAs, used, GL_UNSIGNED_INT, NULL ));
}
And here’s the errors (duplicates were cropped out before posting):
model = 0, trait = 1, Cache->size = 4096
main.c:576: GL_INVALID_OPERATION glBufferData ( GL_ARRAY_BUFFER, Cache->size, Cache->addr, GL_DYNAMIC_DRAW )
main.c:585: GL_INVALID_OPERATION glVertexAttribPointer ( location, values, GL_FLOAT, GL_FALSE, 0, NULL )
main.c:593: GL_INVALID_OPERATION glBufferData ( GL_ELEMENT_ARRAY_BUFFER, used * sizeof(uint), Trait->addr, GL_DYNAMIC_DRAW )
model = 0, trait = 2, Cache->size = 4096
main.c:576: GL_INVALID_OPERATION glBufferData ( GL_ARRAY_BUFFER, Cache->size, Cache->addr, GL_DYNAMIC_DRAW )
main.c:585: GL_INVALID_OPERATION glVertexAttribPointer ( location, values, GL_FLOAT, GL_FALSE, 0, NULL )
main.c:593: GL_INVALID_OPERATION glBufferData ( GL_ELEMENT_ARRAY_BUFFER, used * sizeof(uint), Trait->addr, GL_DYNAMIC_DRAW )
main.c:596: GL_INVALID_OPERATION glDrawElements( Strip->DrawAs, used, GL_UNSIGNED_INT, NULL )
model = 1, trait = 1, Cache->size = 4096
main.c:576: GL_INVALID_OPERATION glBufferData ( GL_ARRAY_BUFFER, Cache->size, Cache->addr, GL_DYNAMIC_DRAW )
main.c:585: GL_INVALID_OPERATION glVertexAttribPointer ( location, values, GL_FLOAT, GL_FALSE, 0, NULL )
main.c:593: GL_INVALID_OPERATION glBufferData ( GL_ELEMENT_ARRAY_BUFFER, used * sizeof(uint), Trait->addr, GL_DYNAMIC_DRAW )
model = 1, trait = 2, Cache->size = 4096
main.c:576: GL_INVALID_OPERATION glBufferData ( GL_ARRAY_BUFFER, Cache->size, Cache->addr, GL_DYNAMIC_DRAW )
main.c:585: GL_INVALID_OPERATION glVertexAttribPointer ( location, values, GL_FLOAT, GL_FALSE, 0, NULL )
main.c:593: GL_INVALID_OPERATION glBufferData ( GL_ELEMENT_ARRAY_BUFFER, used * sizeof(uint), Trait->addr, GL_DYNAMIC_DRAW )
main.c:596: GL_INVALID_OPERATION glDrawElements( Strip->DrawAs, used, GL_UNSIGNED_INT, NULL )
model = 2, trait = 1, Cache->size = 4096
main.c:576: GL_INVALID_OPERATION glBufferData ( GL_ARRAY_BUFFER, Cache->size, Cache->addr, GL_DYNAMIC_DRAW )
main.c:585: GL_INVALID_OPERATION glVertexAttribPointer ( location, values, GL_FLOAT, GL_FALSE, 0, NULL )
main.c:593: GL_INVALID_OPERATION glBufferData ( GL_ELEMENT_ARRAY_BUFFER, used * sizeof(uint), Trait->addr, GL_DYNAMIC_DRAW )
model = 2, trait = 2, Cache->size = 4096
main.c:576: GL_INVALID_OPERATION glBufferData ( GL_ARRAY_BUFFER, Cache->size, Cache->addr, GL_DYNAMIC_DRAW )
main.c:585: GL_INVALID_OPERATION glVertexAttribPointer ( location, values, GL_FLOAT, GL_FALSE, 0, NULL )
main.c:593: GL_INVALID_OPERATION glBufferData ( GL_ELEMENT_ARRAY_BUFFER, used * sizeof(uint), Trait->addr, GL_DYNAMIC_DRAW )
main.c:596: GL_INVALID_OPERATION glDrawElements( Strip->DrawAs, used, GL_UNSIGNED_INT, NULL )
Any ideas to what I should be looking for? Or even better what I should change?