@Dark_Photon much better now, thanks!
test_run.glb (3.9 MB)
test_run.gltf (20.5 KB)
i did save them but i made small progress over the weekend so prepared content is obsolete anyway.
i changed the way of storing indices from using 4 bytes uint only to 2 bytes ushort mostly & additional 4 bytes uint for complex mesh.
now i have two buffers, both have two views, index view and attribute view.
-
buffer 0: (ushort indices) + (alignment) + (pos + normal, float vec3 interleaving)
-
buffer 1: (uint indices) + (pos + normal, float vec3 interleaving)
file size is a little smaller.
i’m still reading the tutorial section of gltf github repo and trying to make things simple.
so, about scene structure:
-
single scene
-
single root node, no mesh attached, plenty of child nodes on the root node
-
each child node has a mesh attached. each mesh has single mesh primitive.
-
single pbr material for all primitives.
-
no texture or animation
even though my thought on storage type worked, still, i have no clue how buffers are used usually. things like, how many buffers should i use? how does their layout look like? because my first thought back then was “why not just use three buffers for idx, pos, normals. keep them seperated, no concerns on offset, stride.”
is there a rule of thumb among gltf users on how buffer(s) should be used?
Put storage approach aside, i’m also digesting what Don @donmccurdy suggested. bear with me, i’m still familiarizing myself with the concepts here. 
so basically, normal becomes the unique identity of vertices at same location.
i suppose you mean this:
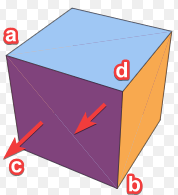
i realized my vertex normals are actually just face normals. norm_a = norm_b = norm_c = norm_triangle_face. so Va has duplicates just come from two purple triangles. then pointing upwards, two identical vertices produced by blue triangles at a. I should drop one for each pair, correct?
but how? i think when i populate indices and attributes at the same time, i can go like “hey, i met this exact same vertex before, it was the no.9. i’m not going to increment my index count here, put 9 instead and skip the attribute data.”
in the end, i will be looking at an index buffer view “longer” than its corresponding attribute buffer view. is this a problem?
Besides, does identifying “same” vertex require me to revisit all vertices i’ve collected at that moment? or perhaps, i should “filter” the collected ones first before the position and normal comparison? anyway, i feel like the dropping process is going to be slow. what would be an optimal duplicates removal strategy?
i guess they are. i googled what hard edge means in gltf context. so if i understand the term correctly, my assets contain only hard edges, just based on the fact that i use face normal as vertex normal. so, i could forget about the normals entirely? only export indices and postions? would it be just all black if provide no normal data at all?
what is “the viewer” exactly? the renderer? the program reads gltf? “flat normals” = face normals?
i went a little further and found out the concept of averaging normals at a particular location. i suppose it produces “soft edge” and could condense my buffer even further. But i think that is a bit too far for me at the moment.
the tools were amazing. after see the stats immediately i realize some of my meshes were just copies, different merely in terms of translation. i need to look more into it, see if i could put more transformations to reduce copies.
i must say you guys do awesome works. tutorials, toolchains are excellent. i appreciate your help!