Hi all,
I am new to OpenCL and to this forum. I wrote a simple application for my purposes to measure the peak FLOP/s of a device in OpenCL. I wanted to check how the datatypes affect the performance.
Basically I just ported my older code from CUDA in order to compare the results as I am considering OpenCL as an alternative. It is based on a simple FMAD code to maximize the throughput.
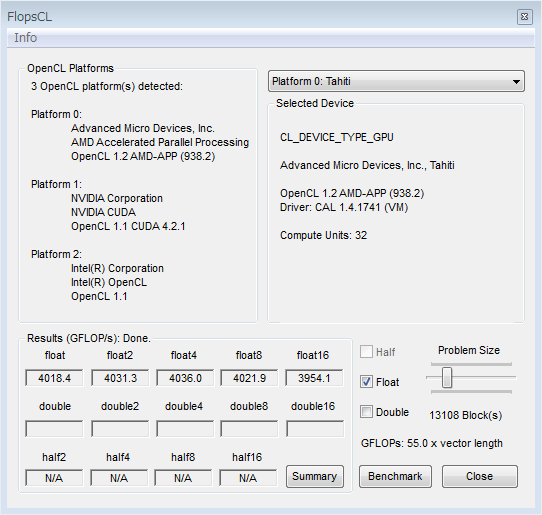
I programmed it under Windows as I couldn’t make NVIDIA and ATI GPUs work together in Linux.
So here’s my first question - has anyone succeeded having OpenCL capable GeForce/TESLA and Radeon in Linux? I’ve noticed that the drivers do something with the kernel, hence the problem.
The second one is related to OpenCL - Sometimes when I run the program on weaker GPUs (i.e. mobile ones) I get an error indicating that it is out of the resources.
Is there any way of getting information about that in advance - before actually running a kernel?
The GPU driver crashes sometimes because of that, it would be good to avoid that.
Anyway, you can download the exe here
http://olab.is.s.u-tokyo.ac.jp/~kamil.rocki/FlopsCL.exe
or here
http://olab.is.s.u-tokyo.ac.jp/~kamil.r … jects.html
and test it. So far I’ve run it on AMD, Intel and NVIDIA platforms and several ATI/NVIDIA GPUs + Intel Sandy Bridge/Ivy Bridge CPUs. Seems to give proper results. Any comments/suggestions appreciated.
The problem size that can be adjusted is the number of workgroups (I named it ‘Blocks’ as in CUDA). If you are planning to use a weaker GPU you might want to decrease it. Larger problem give more precise measurements on average.
Feel free to use and share it if you find it useful.
Kamil