Hi,
I’m working on an OpenCL IDE for Windows (and possibly in the future Mono/Linux/Mac OS), wrappers around the implementations of OpenCL by ATI and NVIDIA which add more robust error handling, etc, and C# wrapping libraries with completely integrated documentation and error handling. So far, I’ve written a few thousand lines of C++, C++/CLI, and C#, and a couple thousand more lines of C# which parses the cl.h, Khronos man pages, and neatly wraps all the C-line APIs into object oriented apis with enumerations, extra checks, workarounds for platform/device speific bugs, etc, etc. At this point, my C# wrapper generator writes out about 5,000 lines of C++ code (soon to work with Linux as well), and by the time I’m finished with it, it will write out at least another 4,000 lines of C++/CLI and C#. Basically, I have a mini C++/CL.H header to C++/C++/CLI, C#, and C++ + “P/Invoke C#” (for Linux) :^)
In addition to all this work (both x64 and x86 – I have dual boot configurations on virtual hard drives to test the Windows variants, and separate installations of Linux to test those), I’m making my code export an OpenCL.DLL which can target a remote Linux (or Windows) box. One of the advantages of the implementation of running Linux and using OpenCL vs Windows is that the Linux OpenCL does not require a monitor to be attached (which is useful when you have 30-50+ customer cluster nodes being built in house on any given day and want to be able to test compute code or stress test on those GPUs without going into the noisy server testing rooms).
The questions I have are:
-
What kind of membership does my company require to use the OpenCL name to market these (as of now unnamed) products? Can I get away with just developing these products and doing my own testing without membership? I have discovered many, many bugs in ATI and NVIDIA implementations in the course of writing and testing my code and my wrappers, and have worked around all of them with unit tests in my code generator, including some nasty crashing bugs, so I’m reasonably certain that the Khronos certification doesn’t indicate a reasonable amount of testing to the OpenCL spec and/or documentation, and that my implementation adds value.
-
In the course of my writing these generated wrappers, error handling, and documentation integration, I have come to notice many inconsistencies with the OpenCL documentations, annoyances with the APIs, and plenty of errors between the way that different implementations deal with ambiguous documentations that I need answers to. For example: if I’m writing an “ICD”, how does GetExtensionFunctionAddress work? By this I mean that I’ll have multiple underlying instances of OpenCL, and someone calls my OpenCL.DLL with clGetExtensionFunctionAddress( “FOO” ); And then I go asking my internal OpenCL.DLL implementations to get extension FOO. But which one do I return? I really don’t expect an ATI extension to work on an NVIDIA device or vice-a-versa. Also, I don’t expect one of my extensions (if I should implement them) would work against an untested OpenCL implementation. Is it clear what error I need to return if I have a cl_mem from one OpenCL.DLL and a cl_mem from another OpenCL.DLL and someone attempts to enqueue a Copy command from one device to another? Perhaps I can issue some synchronization, copy the buffer from one buffer to host memory, and copy from host memory to the other buffer… and what if I want to represent multiple devices as one device and enable a context which spans those virtual devices to do that…
-
Finally, is there any interest in a commercial OpenCL IDE? What might you be willing to pay for something which made it easy to write OpenCL kernel code and get C++ or simple C# code which turns your kernel into a C#/C++ method + static lib or DLL to wrap CL?
-
Is there any interest in code which tests your OpenCL implementation for holes, failure to return appropriate error codes or returning error codes at the wrong time/in the wrong method, crashes in the compiler, crashes in allocating memory or using more memory than allocated? Etc?
-
Finally, is there any interest in running your OpenCL code against remote machines with different CPUs and GPUs to test performance against a large-ish set of current, old, really old, and perhaps new devices as they are disclosed or as they are available in the market, etc?
Feel free to PM me or reply below. I’ll check it sporadically. My email isn’t public…
My test machine has 4 different GPUs and 8 CPU cores (all of them can be run simultaneously with OpenCL – it’s a sight to see, though my next test machine will soon have something like 48 CPU cores and 3200 to maybe up to 6400 GPU cores… all on one motherboard), but we have one box with 8 different x16 GPUs in it (that computer costs something around $10,000 + 8 GPU costs, and it’s a royal pain to configure, and it makes more noise than you want to imagine…).
Anyway, here’s a screenshot of my generator:
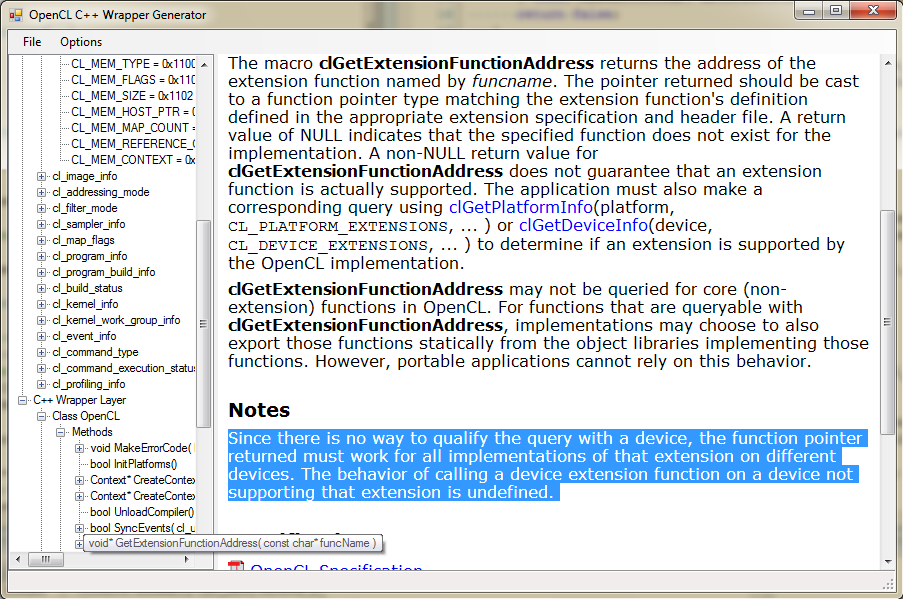
And here’s an out-of-date early screenshot of my IDE (the Cypress / Radeon HD 5870 in this case is underclocked to 400MHz - 850MHz is the nominal value):
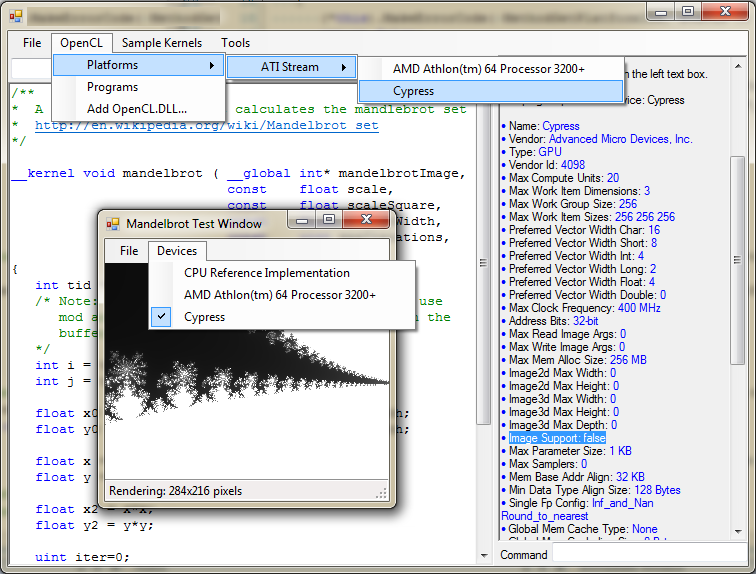
Thanks!