Did someone test Vulkan compute shader nad OpenCL Image2D R/W bandwidth on Adreno GPUs ?
ImageFormat: rgba32f
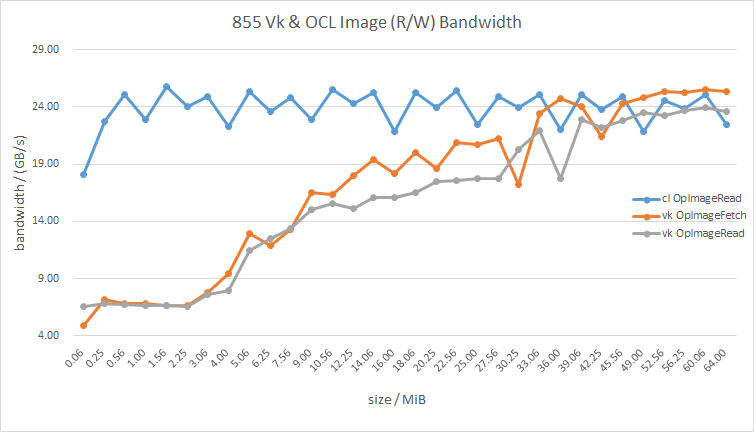
Why the bandwidth performance of Vulkan is lower than OpenCL when data size is small?
And I check the SPIR-V of OpenCL and Vulkan, they just use the same instruction (OpImageRead / OpImageWrite).
The kernel code of Vulkan and OpenCL as follows:
Why the performances are different? OpenCL can reach the peak performance when data size is small, but Vulkan cannot. Is that relavant to the OpenCL and Vulkan drivers?
How are you detecting the “bandwidth”? Broadly speaking, “bandwidth” applies to a property of the hardware, which is immutable and doesn’t change from API to API. What changes is the software overhead of trying to use that bandwidth.
It’s more likely that you’re measuring throughput: the amount of stuff your code can shove through the bandwidth. This therefore includes things like per-dispatch overhead and the like.
Also, your workgroup size in Vulkan is pretty small. In fact, I’m not sure that “0” is even a valid size.
How I define throughput: throughput = (Input_size) / (timeElapsed / 2);
where (input_size = output_size). What I do not understand is why the results are different between OpenCL and GLSL(Vulkan). So driver is the reason???


 .
.