I wrote a simple vulkan app that render 500 cube. I got poor performance from my multithreading secondary command buffer recording, each thread has one commandbuffer and one commandpool, I got ± 900 fps, while on single threading with one primary commandbuffer recording gave me ±4000 fps.What strange is, single threading secondary commandbuffer recording gave me better performance than multithreading with ± 3000 fps.So far i’ve tried ctpl threadpool, sascha willems’ threadpool, my own threadpool code and even std::thread without threadpool, and dynamical get function pointer from vkGetDeviceProcAddr and ofcource on release build on vs 2022 and validation layer off.
My spec :
Intel Core i7 10700k.
Nvidia GeForce RTX 3070 driver version 496.76
16GB RAM
Windows 11 Home.
the code snippet:
void CommandBufferVulkan::DrawMultiThread(uint32_t threadIndex, const std::vector<DrawIndexedMultiThreadInfo>& drawInfo, uint32_t firstIndex, uint32_t lastIndex)
{
const PerThreadCommandBuffer& perThreadCommandBuffer = mPerThreadCommandBuffers[mCurrentFrame][threadIndex];
VkCommandPool commandPool = perThreadCommandBuffer.CommandPool;
VkCommandBuffer commandBuffer = perThreadCommandBuffer.CommandBuffer;
vkResetCommandPool(mpDeviceVulkan->GetDeviceHandle(), commandPool, 0);
VkCommandBufferInheritanceInfo inheriteInfo = {};
inheriteInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_INHERITANCE_INFO;
inheriteInfo.renderPass = mpCurrentRenderPass->GetRenderPassHandle();
inheriteInfo.framebuffer = mpCurrentFramebuffer->GetFramebufferHandle(mCurrentFrame);
VkCommandBufferBeginInfo cmdBufferBeginInfo = {};
cmdBufferBeginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
cmdBufferBeginInfo.pInheritanceInfo = &inheriteInfo;
cmdBufferBeginInfo.flags = VK_COMMAND_BUFFER_USAGE_RENDER_PASS_CONTINUE_BIT | VK_COMMAND_BUFFER_USAGE_SIMULTANEOUS_USE_BIT;
vkBeginCommandBuffer(commandBuffer, &cmdBufferBeginInfo);
vkCmdSetViewport(commandBuffer, 0, (uint32_t)mCurrentViewports.size(), mCurrentViewports.data());
vkCmdSetScissor(commandBuffer, 0, (uint32_t)mCurrentScissors.size(), mCurrentScissors.data());
std::vector<VkDescriptorSet> globalSets;
const DrawIndexedMultiThreadInfo& di_1 = drawInfo[firstIndex];
for (uint32_t i = 0; i < di_1.PGlobalDescriptorSetBindInfo->PDescriptorSets.size(); ++i)
globalSets.push_back(di_1.PGlobalDescriptorSetBindInfo->PDescriptorSets[i]->GetDescriptorSetHandle());
vkCmdBindDescriptorSets(commandBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, di_1.PGlobalDescriptorSetBindInfo->PPipelineLayout->GetPipelineLayoutHandle(),
di_1.PGlobalDescriptorSetBindInfo->FirstSet, (uint32_t)globalSets.size(), globalSets.data(), 0, nullptr);
PipelineVulkan* pPipeline = nullptr;
for (uint32_t i = firstIndex; i < lastIndex; ++i)
{
const DrawIndexedMultiThreadInfo& dii = drawInfo[i];
if (dii.PPipelineVulkan != pPipeline)
{
VkPipeline pipeline = dii.PPipelineVulkan->GetPipelineHandle();
vkCmdBindPipeline(commandBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, pipeline);
pPipeline = dii.PPipelineVulkan;
}
std::vector<VkDescriptorSet> sets;
for (uint32_t j = 0; j < dii.DescriptorBindInfo.PDescriptorSets.size(); ++j)
sets.push_back(dii.DescriptorBindInfo.PDescriptorSets[j]->GetDescriptorSetHandle());
vkCmdBindDescriptorSets(commandBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, dii.DescriptorBindInfo.PPipelineLayout->GetPipelineLayoutHandle(),
dii.DescriptorBindInfo.FirstSet, (uint32_t)sets.size(), sets.data(), 0, nullptr);
vkCmdPushConstants(commandBuffer, dii.DescriptorBindInfo.PPipelineLayout->GetPipelineLayoutHandle(), dii.PushConstantStage, 0, dii.PushConstantSize,
dii.PPushConstantData);
VkBuffer vertexBuffer = dii.PVertexBuffer->GetBufferHandle();
VkBuffer indexBuffer = dii.PIndexBuffer->GetBufferHandle();
VkDeviceSize offset = 0;
vkCmdBindVertexBuffers(commandBuffer, 0, 1, &vertexBuffer, &offset);
vkCmdBindIndexBuffer(commandBuffer, indexBuffer, 0, VK_INDEX_TYPE_UINT32);
vkCmdDrawIndexed(commandBuffer, dii.IndexCount, 1, 0, 0, 0);
}
vkEndCommandBuffer(commandBuffer);
}
void CommandBufferVulkan::DrawIndexedMultiThread(const std::vector<DrawIndexedMultiThreadInfo>& info)
{
if (info.size() < mpWorkerPool->GetWorkerCount())
{
printf("Draw count lower than num of thread!\n");
return;
}
uint32_t threadCount = (uint32_t)mpWorkerPool->GetWorkerCount();
uint32_t drawCountPerThread = (uint32_t)(info.size() / threadCount);
uint32_t drawCountPerThreadMod = info.size() % threadCount;
uint32_t firstIndex = 0;
uint32_t lastIndex = drawCountPerThread;
VkDevice device = mpDeviceVulkan->GetDeviceHandle();
std::vector<uint32_t> firstIndexV(threadCount);
std::vector<uint32_t> lastIndexV(threadCount);
for (uint32_t i = 0; i < threadCount; ++i)
{
if (i == (threadCount - 1))
{
lastIndex += drawCountPerThreadMod;
firstIndexV[i]=firstIndex;
lastIndexV[i] = lastIndex;
}
else
{
firstIndexV[i] = firstIndex;
lastIndexV[i] = lastIndex;
firstIndex += drawCountPerThread;
lastIndex += drawCountPerThread;
}
}
for (uint32_t i = 0; i < threadCount; ++i)
{
mpWorkerPool->PushWork(i, [=]()
{
DrawMultiThread(i, info, firstIndexV[i], lastIndexV[i]);
}
);
}
mpWorkerPool->WaitIdle();
/*
for (uint32_t i = 0; i < threadCount; ++i)
DrawMultiThread(i, info, firstIndexV[i], lastIndexV[i]);
*/
std::vector<VkCommandBuffer> commandBuffers;
for (uint32_t i = 0; i < mPerThreadCommandBuffers[mCurrentFrame].size(); ++i)
commandBuffers.push_back(mPerThreadCommandBuffers[mCurrentFrame][i].CommandBuffer);
vkCmdExecuteCommands(mCurrentVkCommandBuffer, (uint32_t)commandBuffers.size(), commandBuffers.data());
}
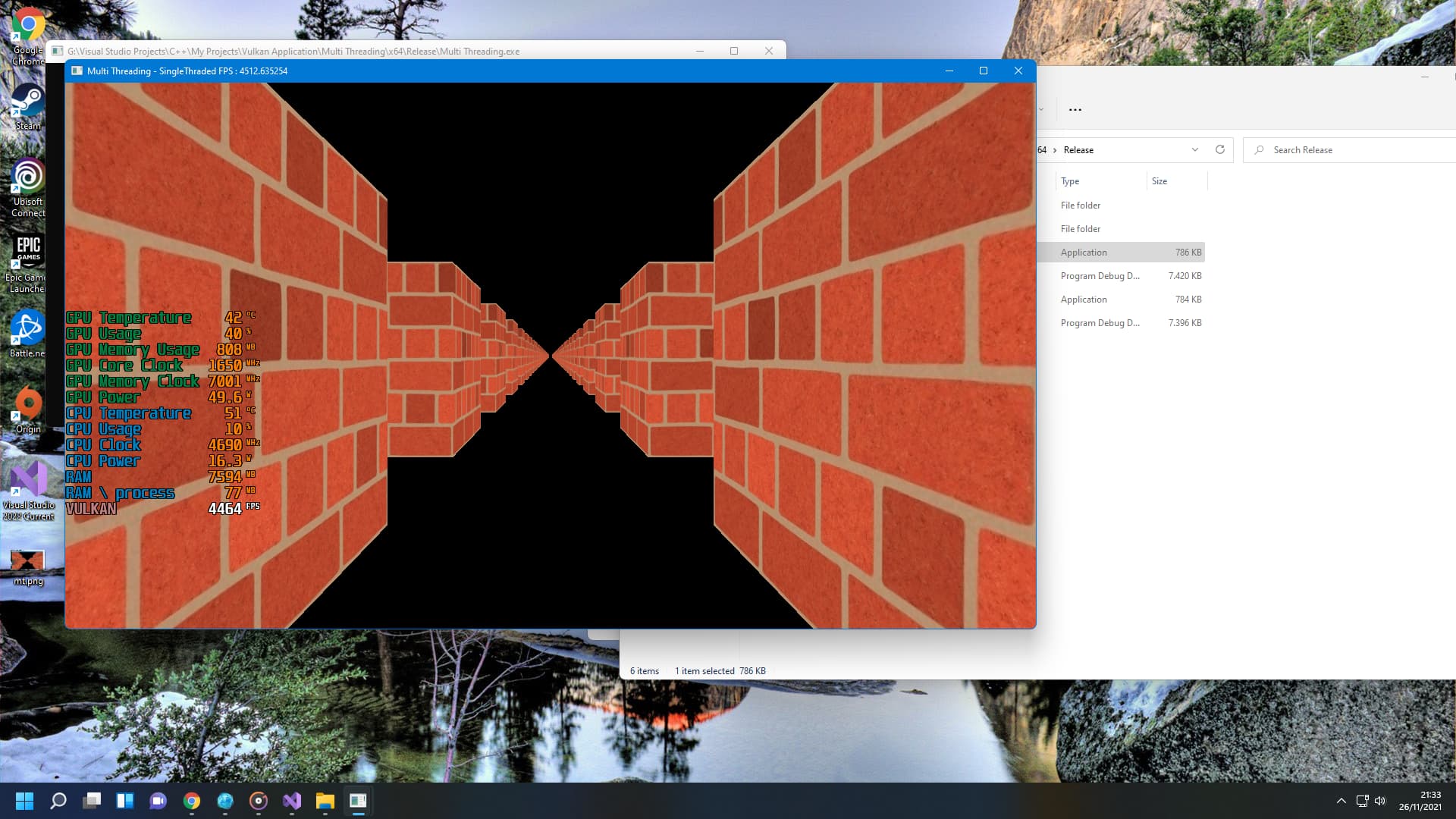
mt screenshot:

st screenshot:
st secondary command buffers recording screenshot:
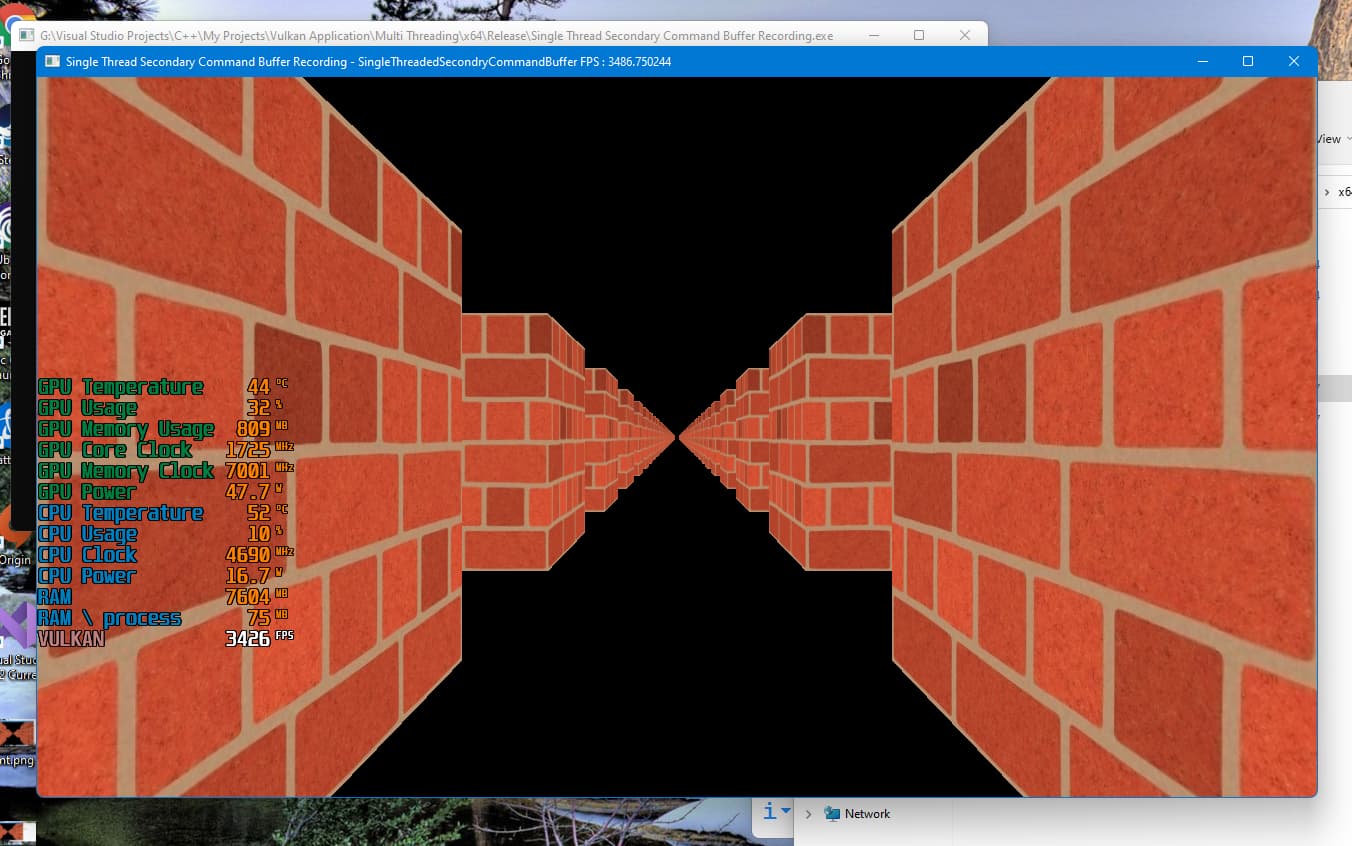
Please guide me.