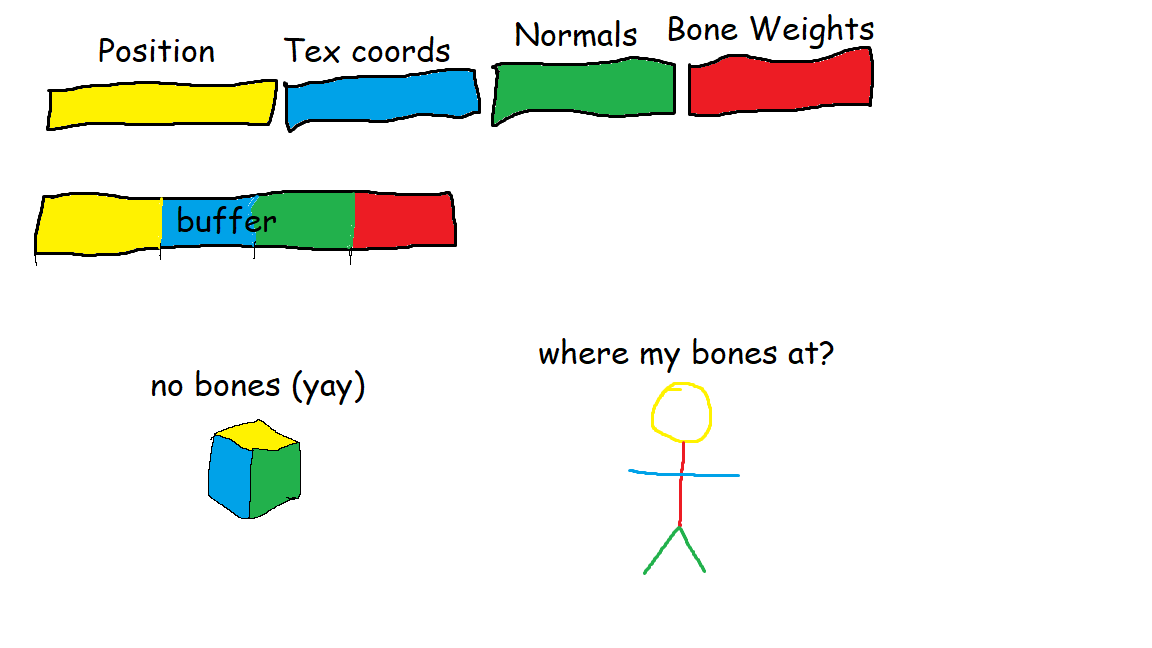
A lot of people in the industry recommend using non-interleaved vertex buffers.I have been reading a lot about this concept recently, and I have been wondering how to properly put this into practice.
From what I understand, this involves loading each bit of vertex data into their own chuncks of memory, and then assigning those chunks input bindings during pipeline creation. Then when binding the vertex buffer, you provide binding offsets for each chunk of data.
Then when you issue a drawing command it fetches everything nicely and in order because all the values are loaded from their offset in the buffer and VertexIndex.
Now lets say that not every mesh I plan to draw with this shader will have the same amount of attributes.
For example, what if I plan to draw a mesh that has a skeleton. Becuase not every mesh I want to draw has the same number of attributes, VertexIndex will not always fetch the correct data.
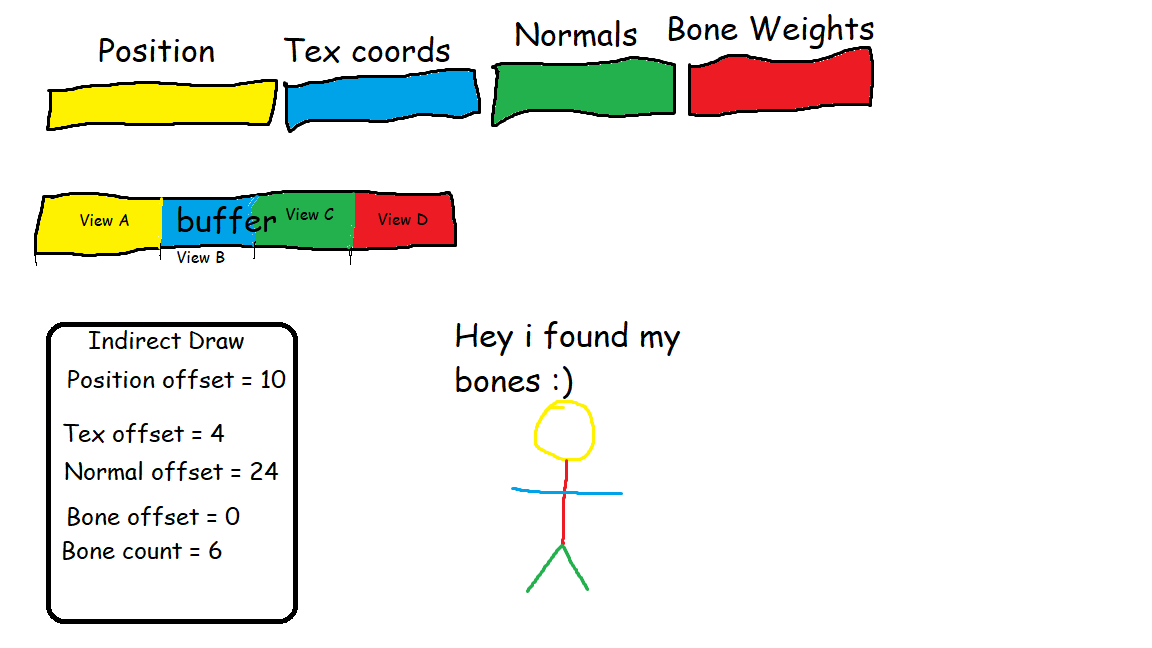
A solution could be providing an offset into the individual attribute chunks at draw time, but as things currently are, you may only provide a single vbo offset in a draw command.
Another solution could be to drop vertex input attributes altogether, and load everything from SSBOs using draw indirect, and insert the individual offsets in your draw command structure.
It seems like I will probably have to go with the SSBO option if I want this to work. If you couldn’t tell already, I want to avoid having to switch shaders during drawing, so I want to cram as much functionality into one uber shader as possible. I am here for any feedback you have, or possible performance-friendly(er) solutions before I start reworking my engine. So please let me know if you think that this will perform well, or if I should stop being a nutjob and just use multiple shaders.
I can understand specific usage scenarios where it might be useful. But there’s no reason to do it by default.
… then you’ve already lost. Especially since:
Then your vertex shader is going to have to look substantially different, isn’t it? Not only will it have to read an extra attribute, but it’s going to have to take an array of matrices to index into, do a bunch of transforms for each non-zero weight, etc, none of which will happen for non-skeletal meshes.
It’s a different shader at that point.
If you change the vertex format, you have changed the shader.
You can’t provide any “vbo offset” in a draw command. Indexed rendering commands can provide an index offset (the base vertex), as well as a byte offset for where to start reading from in the index buffer. But none of those apply (directly) to vertex buffers.
But even that’s a side point. Vertex formats (ie: how to read and interpret vertex buffer data) are baked into the pipeline and cannot be changed without changing the pipeline. If your pipeline takes 4 attributes, then it takes 4 attributes. No more, no less.
Pretty much every commercial game engine where heavy performance optimizations like per triangle culling are involved. It allows for better fetching of individual attributes, as it does not have to fetch the entire vertex structure.
I mean I was just gonna use a conditional in the shader based off of info contained in the draw structure (my vertex shader has access to the buffer containing commands). But that said, I’ve also seen people say using conditionals like this can be bad for performance.
When I say vbo offset, I refer to the base vertex, I use the terms interchangebly. Sorry for any confusion.
I guess I should have been more specific. I of course would still have to bind any possible chunks of data even if not every mesh will use them, as the pipeline can not change the baked amount of input attributes. Would something like this create unessessary overhead?
I am grateful for your response, but I can’t say that this helps me as much is it critiques my poor choice of words. Are you recommending that I use multiple shaders over loading vertex attributes from an SSBO?
Can you give me a link to something? I hadn’t heard about some broad switchover in modern game engines to non-interleaved arrays. Especially since, if you arrange your data as you suggest, where each mesh’s position data is right next to its normal data and so forth, then each mesh’s draw call needs to have a bunch of offsets applied per binding point before drawing. If you have all your meshes with the same vertex format contiguously in the same block of memory, you can draw them all with a single draw call. Indeed, you can build up a single multi-draw indirect call that draws all of them in one shot.
To do this with the method you suggest requires putting all of the positions for each mesh contiguously, then all the normals, etc. This is doable, but it means the uploads of vertex data are scattered. And it would be difficult to add a new mesh, unless you reserved space between each array for that.
Note that we’re talking about the specific case of vertex attributes, not general data oriented design ideas of “structs of arrays” rather than “arrays of structs”.
If there’s an attribute there that you don’t use, the GPU is still going to try to read it. Even if you bind a buffer region that isn’t used, the GPU is still going to spend the time it takes to read and decode the information your shader never uses. Your vertex format says that there’s an attribute there, so it will be read.
If using a separate pipeline is not an option, it would be better to read the optional vertex data manually. That is, specifically the optional data; any mandatory data should still come from attributes.