I am trying to understand, how stereoscopic pairs are created. On the internet I found a lot of information about that, but I don´t know which techniques are still actual.
On what I found, I think there are some different aproaches:
The scene is rotated or shifted to generate the left and right eye view. You have only one camera.
Something about two projection centers. I don´t realy understand.
I think number 3 is the technique which is used nowadays, right? The webpage linked at number 3 says something about a method called “off-axis”. In other sources I found number 2 is called like this. Is it the same?
1 and 3 are the same thing. Shifting the scene is equivalent to a second camera. Not sure about 2, but many times you have a “focus” point both cameras point at so you rotate the camera a small degree around that point. In the end you want two images, one image offset from the other. Then you have to get one image into one eye and the other image in the other eye. Polarized glasses is one method, where your left lens filters out the right image and the right image filters out the left.
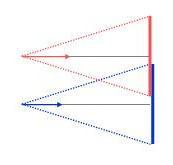
first picture is a wrong method.
2) and 3) are almost the same in fact, the difference being that 2) does not need black vertical borders on the screen.
So 2) is best. And even better is to place left and right cameras exactly at the place the user has its eyes, knowing the size and distance of the screen. And on top of that, tracking eyes in real time
I have another questions to the techniques above. These techniques require to render every picture twice. Isn´t that pretty slow?
The time you need for rendering wouldn´t matter that much for annimation movies. But what about applications you interact with, like medical systems or video games?
It is not “pretty slow”, it is only twice as slow in the worst case.
An example, instead of rendering 120fps (which gets capped to 60hz with vsync), render 60fps with stereo, it is much better.
As ZbuffeR stated, twice as slow is the worst case. So many games and other applications do a lot of render-to-texture for things like environment maps and dynamic textures like fire and such. Those don’t need to be rendered twice. In fact, if you look at nVidia’s slides on automatically making a game 3D, they use some pretty cool tricks to decide which textures need to be rerendered, and according to them quite a bit of the render calls now days isn’t for the final render. Also, work like setting up VBOs and such only need to be done once.
NVIDIA® 3D Vision™ automatically transforms hundreds of PC games into full stereoscopic 3D right out of the box, without the need for special game patches.
How can the NVIDIA software do this? It cannot be one of the stereo rendering methods above, because that has to be integrated in the game engine I think. Is it simple pixel shifting?
It cannot be one of the stereo rendering methods above, because that has to be integrated in the game engine I think. Is it simple pixel shifting?
In fact the nivida driver is somewhat part on the game engine. For 3Dvision, it stores rendering commands and view projections, and when swapbuffers is called, it replays the commands on a slighty changed projection, like methods above.
That means the following problems happen (tried) :
badly choosen depth (focal plane is too far / too near for a game)
most multipass and post-processing effects are broken (bloom, shadows, …)
hud and 2D elements are messy
“Supported” games are detected by the nv driver and some parameters are tweaked or disabled to lessen artifacts (but you loose visual features too).

{kind=link}