Hi!
My apologies.
I’m currently attempting to implement a vulkan based deferred renderer and having trouble debugging/figuring out if the performance characteristics i’m seeing on my end are expected or if i’m loosing performance due to inefficient utilisation of the API. (Still working out how to synchronize execution/memory via barriers/external subpass dependencies.)
During debugging i noticed that the execution time on the GPU on some shaders was rather high (basically everytime a 3D mesh was written into the GBuffer over a larger portion of the screen) or even during postprocessing effects like SSAO.
Note that i’m testing this on a GTX 1060 at FullHD (1080p) resolution. I’m aware that this gpu model is considered to be old nowadays but still i didn’t expect to have this kind of (horrible) performance that i’m experiencing here.
Example of the SSAO shader:
#version 450
#extension GL_ARB_separate_shader_objects : enable
#include "normalCompression.glsl"
layout(binding = 0) uniform SSAOshaderUniform {
mat4 invViewProj;
mat4 projection;
mat4 normalViewMatrix;
vec4 ssaoKernel[32];
vec2 resolution;
vec2 noiseScale;
int kernelSize;
float radius;
float bias;
} ubo;
layout(binding = 1) uniform sampler2D texSsaoNoise;
layout(binding = 2) uniform sampler2D texViewDepth;
layout(binding = 3) uniform sampler2D texViewNormal;
layout(location = 0) in vec2 fragTexCoord;
layout(location = 0) out vec4 outColor;
vec3 depthToWorld(sampler2D depthMap,vec2 texcoord,mat4 inverseProjView){
float depth = texture(depthMap,texcoord).r;
//vec4 position = vec4(texcoord,depth,1.0);
vec4 position = vec4(texcoord* 2.0 - 1.0,depth,1.0);
position = ((inverseProjView)*position);
return vec3(position/ position.w);
}
vec3 reconstructViewPos(vec2 texcoord,float depth,mat4 invProj){
vec4 clipSpaceLocation;
clipSpaceLocation.xy = texcoord * 2.0f - 1.0f;
clipSpaceLocation.z = depth;
clipSpaceLocation.w = 1.0f;
vec4 homogenousLocation = invProj * clipSpaceLocation;
return homogenousLocation.xyz / homogenousLocation.w;
}
//Plane equation. Define a plane pointing towards the +Z axis, use "coords" to select a point on the plane. Returns the z-coordinate at this specific point
float calcDepthOnPlane(vec3 planeNormal,vec2 coords){
return (-planeNormal.x * coords.x - planeNormal.y * coords.y)/planeNormal.z;
}
void main()
{
int kernelSize = ubo.kernelSize;
float radius = ubo.radius;
float bias = ubo.bias;
//position and normal should be in viewspace!
vec2 fragPosCentered = (floor(fragTexCoord * ubo.resolution)+vec2(0.5,0.5))/ubo.resolution;//ivec2(floor(fragTexCoord * resolution));
vec3 fragPos = depthToWorld(texViewDepth,fragPosCentered,inverse(ubo.projection));//ubo.invViewProj);
vec3 normal = (ubo.normalViewMatrix * vec4(normalDecode(texture(texViewNormal, fragPosCentered).rg),1.0)).xyz;
vec3 randomVec = (texture(texSsaoNoise, fragTexCoord * ubo.noiseScale).xyz * 2.0) - 1.0;
randomVec.z = 0.0;
vec3 tangent = normalize(randomVec - normal * dot(randomVec, normal));
vec3 bitangent = cross(normal, tangent);
mat3 TBN = mat3(tangent, bitangent, normal);
// iterate over the sample kernel and calculate occlusion factor
float occlusion = 0.0;
for(int i = 0; i < kernelSize; ++i)
{
// get sample position
vec3 samplePos = TBN * ubo.ssaoKernel[i].xyz; // from tangent to view-space
samplePos = fragPos + samplePos * radius; //viewspace pos
// project sample position (to sample texture) (to get position on screen/texture)
vec4 offset = vec4(samplePos, 1.0);
offset = ubo.projection * offset; // from view to clip-space
offset.xyz /= offset.w; // perspective divide
offset.xyz = offset.xyz * 0.5 + 0.5; // transform to range 0.0 - 1.0
// get sample depth
float sampleDepth = depthToWorld(texViewDepth,offset.xy,inverse(ubo.projection)).z;//depthToWorld(texViewDepth,offset.xy,inverse(ubo.projection)).z;//texture(gPosition, offset.xy).z; // get depth value of kernel sample
// range check & accumulate
float rangeCheck = smoothstep(0.0, 1.0, radius / abs(fragPos.z - sampleDepth));
occlusion += (sampleDepth >= samplePos.z + bias ? 1.0 : 0.0) * rangeCheck;
}
occlusion = 1.0 - (occlusion / kernelSize);
vec3 fColor = texture(texViewDepth, fragTexCoord).rgb;
outColor = vec4(occlusion,occlusion,occlusion,1.0);
}
Note that i set the kernelsize to 16 and radius to 0.1.
The SSAO is nothing fancy. 1 texture tap for the depth at the fragment pos, (depth is a 32 bit floating point buffer btw), 1 tap for the scene normal (for subpixel accuracy) and then 16 taps of the depth buffer around the kernel. (normalbuffer isn’t touched there.)
Here the output
{kind=link}
And that’s the execution time:
Nsight execution time
{kind=link}
SSAO was taken here with 16 samples with a very low sample radius to make sure that every texelfetch during kernel sampling is close in memory to each other (to check if that’s a caching issue due to large memory jumps which doesn’t seem to be the case). With a bigger radius the execution time gets way worse.
Spending 3-4 ms on SSAO seems a bit excessive for the GPU and the quality of the result hence why i’m wondering if i’m maybe overlooking something on the API end? (Increasing the sampling to 32 taps or increasing the radius can result in the execution time exceeding 5-6 ms. On a GTX 1060.)
Another thing i noticed that Gbuffer rendering also takes a long time.
Here a test where i write into 4 attachments (each having 32 bits) and getting 0.4 ms execution time by rendering a very simple floor. (pointing the camera down to render this over the entire screen worsens this of course.)
Shader:
#version 450
#include "normalCompression.glsl"
#include "normalFilter.glsl"
layout(binding = 1) uniform sampler2D sAlbedo;
layout(binding = 2) uniform sampler2D sNormal;
layout(binding = 3) uniform sampler2D sMetal;
layout(binding = 4) uniform sampler2D sRoughness;
layout(binding = 5) uniform sampler2D sEmissive;
layout(binding = 6) uniform sampler2D sAo;
layout(binding = 7) uniform sampler2D sShadow;
layout(location = 0) in vec3 fragColor;
layout(location = 1) in vec2 vTexcoord;
layout(location = 2) in vec3 vNormal;
layout(location = 3) in vec3 vModelViewPosition;
layout(location = 4) in vec2 fragTexCoordLightmap;
layout(location = 5) in float emissionMultiplier;
layout(location = 6) in mat3 tangentToWorldMatrix;
layout (location = 0) out vec4 gAlbedo;//32 bit RGBA8
layout (location = 1) out vec2 gNormal;//32 bit R16G16
layout (location = 2) out vec2 gNomalGeometry;//32 bit R16G16
layout (location = 3) out vec2 gNormalClearcoat;//32 bit R16G16
void main() {
gAlbedo = texture(sAlbedo, vTexcoord) * vec4(fragColor.rgb,1.0);
vec3 normal = filterNormalMap(sNormal, vTexcoord);
gNormal.xy = normalEncode(normal * tangentToWorldMatrix);
gNomalGeometry.xy = normalEncode(normalize(vNormal));
gNormalClearcoat = gNomalGeometry;
}
Results: (Notice that only the mesh which is marked with the wireframe was rendered into the gbuffer)
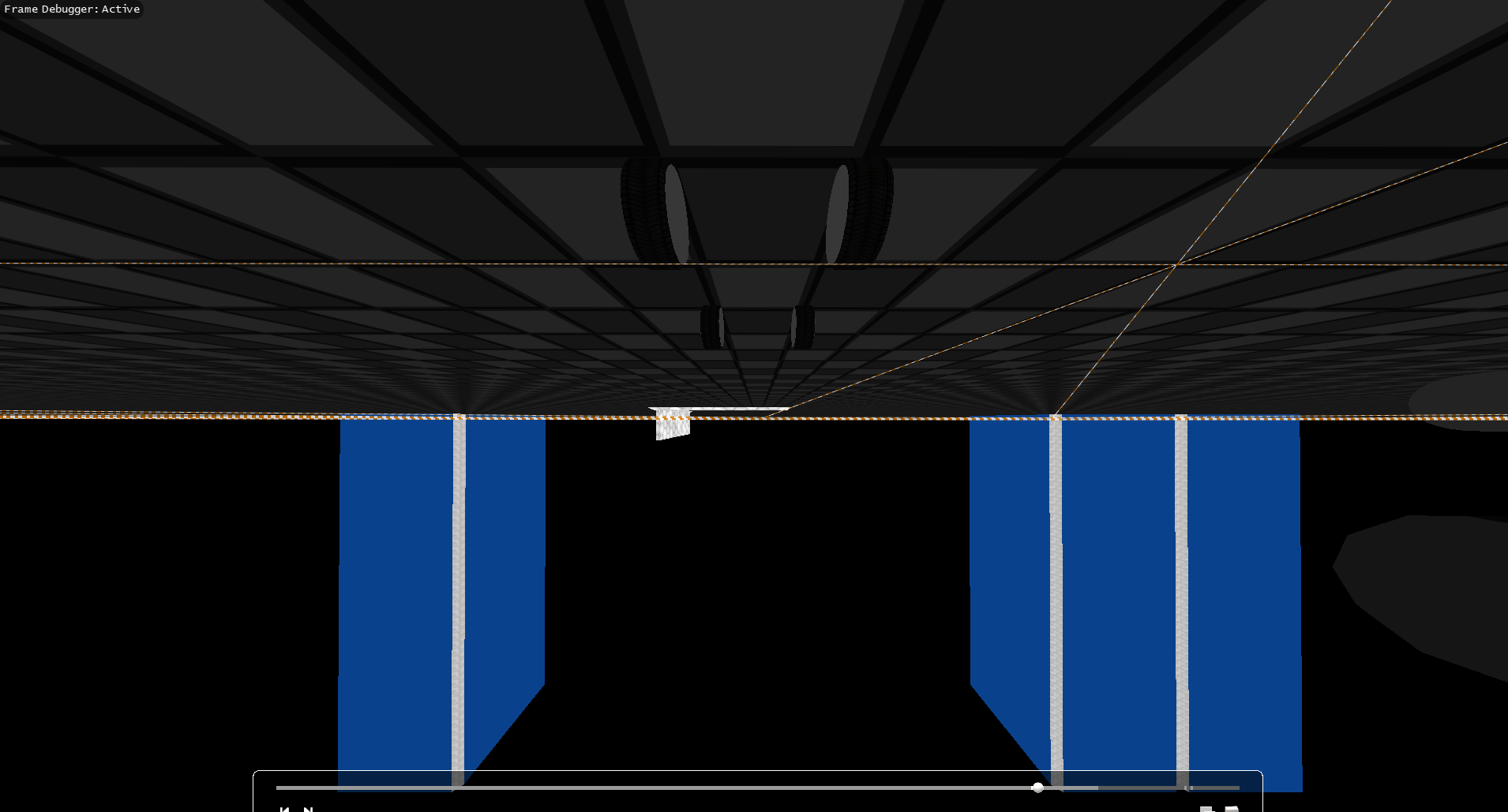{kind=link}
{kind=link}
I noticed that in both cases removing texture writes to the attachments (simply commenting out the line which writes information to the attachment) in the shader reduces the execution time to below 0.1 ms. (so i assume that the write access is the bottleneck?)
My question would be if that’s a “normal” performance characteristic for this GPU or if i’m potentially stalling the GPU pipeline somewhere which leads to this results?
In case that information is needed, i only render with renderpasses which have only one (main) renderpass and no subpasses with this execution/memory dependency:
{
VkSubpassDependency dependency;
dependency.srcSubpass = VK_SUBPASS_EXTERNAL;
dependency.dstSubpass = 0; // First subpass attachment is used in
dependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.srcAccessMask = 0;
dependency.dstStageMask = VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT | VK_PIPELINE_STAGE_LATE_FRAGMENT_TESTS_BIT;
dependency.dstAccessMask = VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_READ_BIT | VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT;
dependency.dependencyFlags = 0;
dependencies.push_back(dependency);
}
{
VkSubpassDependency dependency;
dependency.srcSubpass = 0;
dependency.dstSubpass = VK_SUBPASS_EXTERNAL;
dependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.srcAccessMask = 0;
dependency.dstStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.dstAccessMask = VK_ACCESS_COLOR_ATTACHMENT_READ_BIT | VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT;
dependency.dependencyFlags = 0;
dependencies.push_back(dependency);
}
VkRenderPassCreateInfo renderPassCreateInfo = {};
renderPassCreateInfo.dependencyCount = dependencies.size();
renderPassCreateInfo.pDependencies = dependencies.data();