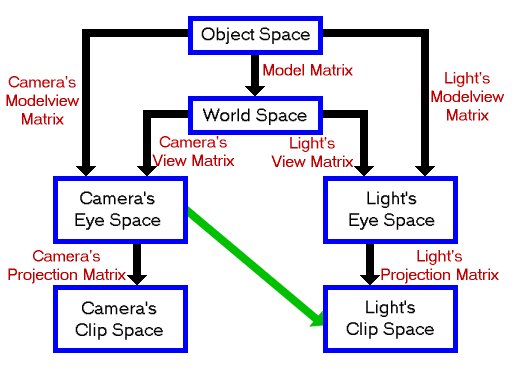
So I’ve been trying to get shadow mapping to work for what feels like an eternity now. Looked all over and even asked on Stack Overflow to no avail. My shadow map renders properly it seems (I would show pictures but this forum and stackoverflow make it needlessly difficult to share information beyond text) so I have come to the conclusion that the problem lies with my fragment positions in light space. I read somewhere that the process of fetching the frag positions in light space is a bit different with deferred. Since I’m storing the values in a texture. But I have no idea how to fix it since I can’t find any information on it. All tutorials that I have found do shadow mapping with forward rendering.
float shadowCalc(vec3 lightDir)
{
vec4 fragPosLS = texture(gFragPosLS, uvs);
vec3 projCoords = (fragPosLS.xyz / fragPosLS.w) * 0.5 + 0.5; //Manually do perspective divison
float shadow;
if(texture(shadowMap, projCoords.xy).r < projCoords.z)
shadow = 0.4;
else
shadow = 1.0;
return shadow;
}
Here is my shadow calculation in the shader. gFragPosLS is a texture I send in which stores all the fragments in light space which I get like this:
vs_out.FragPosLS = LSMat * vec4(position, 1.0f); //Fragment position in light space
The LSMat is a uniform that represents the lightspace matrix which looks like this:
//Create LSMatrix
GLfloat near_plane = 1.0f;
GLfloat far_plane = 10.0f;
glm::mat4 lightProjMat = glm::ortho(-10.0f, 10.0f, -10.0f, 10.0f, near_plane, far_plane);
glm::mat4 lightViewMatrix = glm::lookAt(glm::vec3(-2.0f, 6.0f, -1.0f),
glm::vec3(0.0f, 0.0f, 0.0f),
glm::vec3(0.0f, 1.0f, 0.0f));
shadowBuf.lightSpaceMat = lightProjMat * lightViewMatrix;
So as I said, I suspect the problem lies with how I read the fragment pos lightspace within the light pass. I’m just using regular uv coordinates that I use for everything else but seems like you can’t do that? Any help would be greatly appreciated and if I need to show more code or anything to make it clearer just tell me and I’ll upload more. Thanks.


{kind=link}
![http://pahlavan.se/dump/Rostam_Rendering_2016-08-22_00-12-36.png[/li][/ul]](http://pahlavan.se/dump/Rostam_Rendering_2016-08-22_00-12-36.png%5B/li%5D%5B/ul%5D){kind=link}
![http://pahlavan.se/dump/Rostam_Rendering_2016-08-22_00-13-51.png[/li][/ul]](http://pahlavan.se/dump/Rostam_Rendering_2016-08-22_00-13-51.png%5B/li%5D%5B/ul%5D){kind=link}
{kind=link}
{kind=link}
{kind=link}